This blog post is part of a series detailing my implementation of a fault-tolerant key-value server using the RAFT consensus protocol. Before diving into RAFT and its mechanics, it’s crucial to grasp the concept of a replicated state machine and its significance in building systems that are both fault-tolerant and highly available.
Replicated State Machine
A replicated state machine is essentially a collection of identical machines working together. One machine acts as the “master,” handling client requests and dictating the system’s operations. The other machines, the “replicas,” diligently copy the master’s state. This “state” encompasses all the data necessary for the system to function correctly, remembering the effects of previous operations. Think of a key-value store: the state would be the key-value pairs themselves, replicated across all machines to maintain consistency and resilience. Having the master’s state copied across multiple machines enables us to use these replicas in several ways. They can take over as the new master if the original fails, or handle read operations to reduce the load on the master. Because the state is copied across machines, network issues like latency, packet loss, and packet reordering significantly affect how closely a replica’s state matches the master’s. The difference between the master’s (most up-to-date) state and a replica’s state is known as replication lag. Generally, we aim to minimize this lag, and different systems offer varying levels of consistency (which we will discuss later when covering replication in RAFT).
Aside from application-level replication, which primarily requires context of the state needed for replication or enforces a set of rules for the state that can be replicated, another approach involves replicating the entire machine state at the instruction level. This includes replicating instruction outputs and interrupt behaviour. This method ensures that machines execute the same set and order of instructions and maintain identical memory pages, resulting in an exact replica of the entire machine. However, this approach is more challenging to control, as managing interrupts, I/O, and replicating them to other machines is complex. An example of such an approach is discussed in The Design of a Practical System for Fault-Tolerant Virtual Machines_. This paper details the approach they followed when designing a hypervisor to capture and replicate the state of guest machines.
RAFT - A Consensus Algorithm
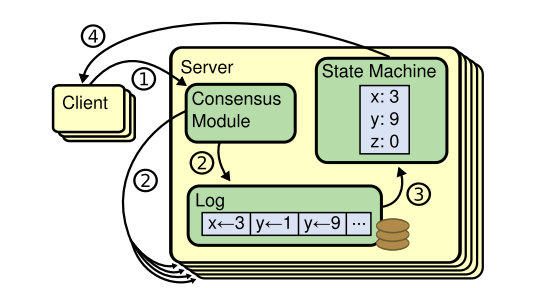 RAFT is a consensus algorithm for managing a replicated log. Consensus algorithms allow a collection of machines to work as a group that can survive failures of some of its members. A replicated state is generally maintained as a replicated log. Each server maintains its own copy of logs, and keeping the replicated log consistent is the job of the consensus algorithm.
RAFT is a consensus algorithm for managing a replicated log. Consensus algorithms allow a collection of machines to work as a group that can survive failures of some of its members. A replicated state is generally maintained as a replicated log. Each server maintains its own copy of logs, and keeping the replicated log consistent is the job of the consensus algorithm.
Let’s take an example of an operation done on a key-value store.
A client sends a command like PUT x=2, which is received by the master server of the group. The consensus module of the server receives this command and appends it to its log.
The master’s consensus module communicates with other servers about this new log and ensures that each server’s log contains the same command in the same order.
Once commands are replicated, each server processes the command on its own state machine, and since the log is the same on each server, the final state on each server results in the same output. As a result, the servers appear to form a single, highly reliable state machine.
RAFT implements this consensus between all servers by electing a leader and giving it the responsibility to decide the sequence of log operation that will be appended and propagated to each member. Flow of logs only happen in one direction from leader to other servers so if a particular server’s sequence does not match to leader’s sequence of logs, leader can instruct the follower (replica) server to erase its log and strictly follow leader itself.
From the RAFT paper: Given the leader approach, Raft decomposes the consensus problem into three relatively independent subproblems, which are discussed in the subsections that follow:
- Leader election: a new leader must be chosen when an existing leader fails.
- Log replication: the leader must accept log entries from clients and replicate them across the cluster, forcing the other logs to agree with its own.
- Safety: if any server has applied a particular log entry to its state machine, then no other server may apply a different command for the same log index.
Logs, State Lifecycle and RPCs
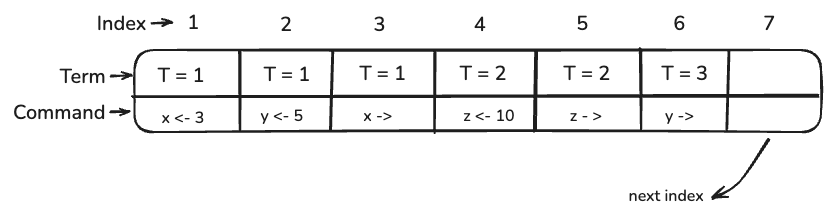
Each LogEntry consists of the command it contains and the term value.
1type LogEntry struct {
2 Command interface{}
3 Term int
4}
Raft divides time into terms of arbitrary length. Terms are numbered with consecutive integers. Each term begins with an election, in which one or more candidates attempt to become leader.
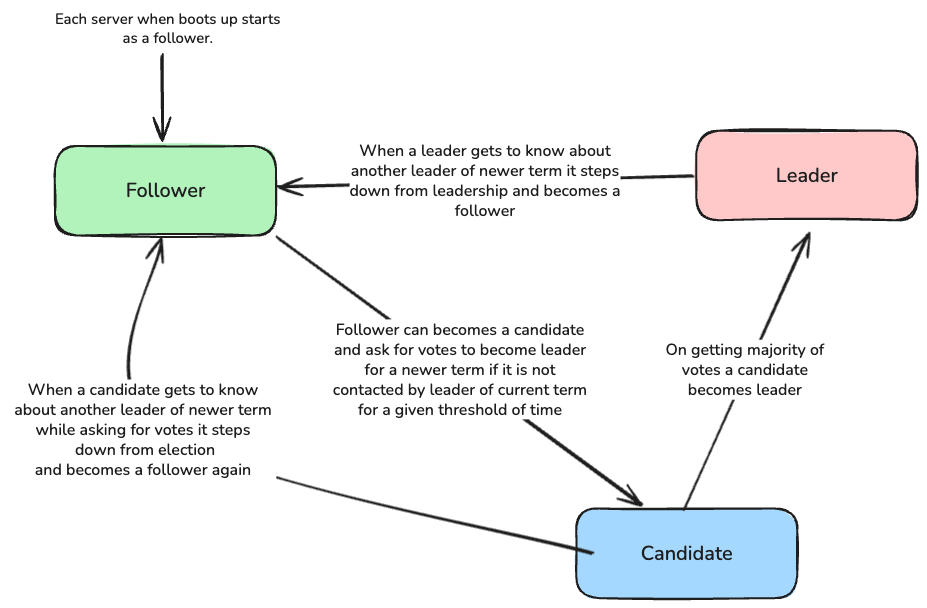
Each server has a role, with only one designated as the Leader for a specific period. The remaining servers are either Followers, who heed the Leader’s communications, or Candidates. Candidates solicit votes from other servers if they haven’t received communication from a Leader within a set timeframe.
1const (
2 StateFollower ServerState = iota
3 StateLeader
4 StateCandidate
5)
Due to variations in timing, different servers might see the changes between terms at different moments. A server might also miss an election or even entire terms. In Raft, terms serve as a logical clock, enabling servers to identify outdated information like old leaders. Every server keeps track of a current term number, which consistently increases. Servers exchange current terms during communication; if one server has a smaller term than another, it updates to the larger term. Should a candidate or leader find its term is outdated, it immediately becomes a follower. A server will reject any request that includes an old term number.
The diagram below illustrates how a server’s role changes under different circumstances.
 To grasp the role of elections and how
To grasp the role of elections and how Term serves as a time marker in RAFT, we must first understand
- How the threshold time is determined, after which a follower can become a candidate and start an election.
- How each server of the cluster communicates with one another
Imagine a cluster of three servers experiencing a network partition, where server 0, the current leader, cannot communicate with servers 1 and 2. If the servers have a fixed timeout value for election, multiple servers might initiate elections simultaneously, resulting in no majority each time, with each server only receiving its own vote. Consequently, the cluster cannot decide on a leader for the next term. With each re-election, a server’s term value (also known as currentTerm) increases by 1. So, when the previous server 0, from, say, term 1, rejoins the cluster after recovery, it will vote for either server 1 or 2, as both are requesting votes for their own currentTerm value, which will now be N if N elections have occurred after server 0 went down, with each server starting its own election and failing to become leader due to the lack of a majority. Even if server 0 votes for one server and a majority is achieved, the new leader needs to communicate with all peers, and if that doesn’t happen quickly, we’ll see another election. Overall, the cluster will be unstable and unable to progress due to election instability.
To resolve this, we introduce a small element of randomness to each server’s election timeout. This minimizes the chance of multiple servers starting elections simultaneously and maximizes the likelihood of a single server triggering a re-election and continuing as leader for subsequent terms.
1func Make(peers []*labrpc.ClientEnd, me int,
2 persister *tester.Persister, applyCh chan raftapi.ApplyMsg) raftapi.Raft {
3 ...
4 // other state initialisation, we will see them later
5 ...
6
7 rf.electionTimeout = time.Duration(1500+(rand.Int63()%1500)) * time.Millisecond
8 go rf.ticker()
9 ...
10 // other state initialisation, we will see them later
11 ...
12
13 }
14
15func (rf *Raft) ticker() {
16 for !rf.killed() {
17 rf.mu.Lock()
18 if rf.state != StateLeader && time.Since(rf.lastContactFromLeader) >= rf.electionTimeout {
19 go rf.startElection()
20 }
21 rf.mu.Unlock()
22
23 // pause for a random amount of time between 50 and 350
24 // milliseconds.
25 heartbeatMS := 50 + (rand.Int63() % 300) // [50, 350)ms time range
26 time.Sleep(time.Duration(heartbeatMS) * time.Millisecond)
27 }
28}
Each RAFT server’s state (We will discuss each state in detail later on):
1type Raft struct {
2 mu sync.Mutex // Lock to protect shared access to this peer's state
3 peers []*labrpc.ClientEnd // RPC end points of all peers
4 persister *tester.Persister // Object to hold this peer's persisted state
5 me int // this peer's index into peers[]
6 dead int32 // set by Kill()
7
8 // Persisted State
9 currentTerm int // latest term server has seen
10 votedFor int // candidateId that received vote in current term
11 log []LogEntry // log entries; each entry contains command for state machine, and term when entry was received by leader
12 snapshotLastLogIndex int
13 snapshotLastLogTerm int
14 // snapshot []byte
15
16 // Volatile state
17 commitIndex int // index of highest log entry known to be committed
18 lastApplied int // index of highest log entry applied to state machine
19 state ServerState // role of this server
20 lastContactFromLeader time.Time // Last timestamp at which leader sent heartbeat to current server
21 electionTimeout time.Duration // time duration since last recieved heartbeat after which election will be trigerred by this server
22 applyCh chan raftapi.ApplyMsg // Channel where a raft server sends it commands to be applied to state machine
23
24 // Volatile leader state
25 nextIndex []int // for each server, index of the next log entry to send to that server
26 matchIndex []int // for each server, index of highest log entry known to be replicated on server
27 applyCond *sync.Cond // Condition validable to signal applier channel to send commands to apply channel
28
29 leaderCancelFunc context.CancelFunc // Go context for a leader, called when we need to cancel leader's context and leader is stepping down
30 replicatorCond *sync.Cond // Leader's conditon variable to signal replicator threads for each peer to either send heartbeat or new logs to each peer
31}
For the communication between servers, RAFT consensus algorithm uses RPC for
- Requesting vote from other peers -
RequestVoteRPC - Propagate changes to log entries from leader to followers -
AppendEntriesRPC - Sending heartbeats from leader to follower -
AppendEntriesRPC with empty log data RPC, or Remote Procedure Call, is a programming paradigm that allows a program to execute a procedure (function, method) on a different machine as if it were a local procedure call. Essentially, it’s a way to build distributed systems where one program (the client) can request a service from another program (the server) over a network. Go providesnet/rpcpackage which abstract most of the work related to serialization of RPC arguments and deserialization at receiving end and the underlying network call with provided data, to know more check Go’snet/rpcpackage
RPC arguments and reply structs as also shown in the original paper (page 4, fig 2)
1type RequestVoteArgs struct {
2 Term int // candidate’s term
3 CandidateId int // candidate requesting vote
4 LastLogIndex int // index of candidate’s last log entry
5 LastLogTerm int // term of candidate’s last log entry
6}
7
8type RequestVoteReply struct {
9 Term int //currentTerm, for candidate to update itself in case someone else is leader now
10 VoteGranted bool // true means candidate received vote
11}
12
13// Invoked by leader to replicate log entries; also used as heartbeat.
14type AppendEntriesArgs struct {
15 Term int // leader’s term
16 LeaderId int // so follower can redirect clients
17 PrevLogIndex int // index of log entry immediately preceding new ones
18 PrevLogTerm int // term of prevLogIndex entry
19 Entries []LogEntry // log entries to store (empty for heartbeat; may send more than one for efficiency)
20 LeaderCommit int // leader’s commitIndex
21}
22
23type AppendEntriesReply struct {
24 Term int // currentTerm, for leader to update itself
25 Success bool // true if follower contained entry matching prevLogIndex and prevLogTerm
26 ConflictIndex int // Followers index which is conflicting with leader's prevLogIndex
27 ConflictTerm int // Followers term of conflicting log
28}
29
30type InstallSnapshotArgs struct {
31 Term int
32 LeaderId int
33 LastIncludedIndex int
34 LastIncludedTerm int
35 Data []byte
36}
Rules Of Election
As we have already seen, an election timeout triggers an election by a given server, which is a Follower. This timeout occurs when the Follower does not receive any AppendEntries RPCs (even empty ones, containing no log) from the leader. When an election is initiated with rf.startElection(), the follower increments its currentTerm by 1 and issues RequestVote RPCs to each of its peers in parallel, awaiting their responses. At this point, three outcomes are possible:
- The Follower gains a majority and becomes the leader.
In this case, the Follower converts to the Leader state, and
setupLeadermethod sets uprf.replicatego routine for each of the other peers in a separate go routine. These go routines are responsible for sending heartbeats and logs usingAppendEntriesRPC calls, We use condition variablereplicatorCondto signal these waiting go threads either when new log entry comes up or when heartbeat timeout occurs. - While waiting for votes, a candidate may receive an
AppendEntriesRPC from another server claiming to be the leader. If the leader’s term (included in its RPC) is at least as large as the candidate’s current term, then the candidate recognizes the leader as legitimate and of newer term hence reverts to the follower state. If the term in the RPC is smaller than the candidate’s current term, the candidate rejects the RPC and remains in the candidate state. - A candidate neither wins nor loses the election. If many followers become candidates simultaneously, votes could be split, preventing any single candidate from obtaining a majority. When this happens, each candidate will time out and start a new election by incrementing its term and initiating another round of
RequestVoteRPCs. The randomness in the election timeout helps prevent split votes from happening indefinitely.
According to the current rules, a server receiving a RequestVote RPC with a Term greater than its own should grant its vote. However, this could lead to an outdated server with an incomplete log becoming leader. Since the leader is responsible for log propagation and can overwrite follower logs, it’s possible for such an outdated leader to erase already committed logs for which clients have received responses - an undesirable outcome.
Re-examining the RequestVoteArgs reveals that, in addition to Term, the struct includes LastLogIndex and LastLogTerm, representing the candidate’s last log entry’s index and term, respectively. These values help determine if the candidate’s log contains at least the latest committed entries. The rules for verifying this when voting are straightforward:
Raft determines the more up-to-date of two logs by comparing the index and term of their last entries. If the last entries have different terms, the log with the latter term is considered more up-to-date. If the logs share the same last term, the longer log is deemed more up-to-date.
Let’s understand how RAFT prevents a stale server from winning an election and becoming a leader with the help of an example:
consider a follower A that gets partitioned away from the rest of the cluster. Its election timeout fires, so it increments its term and starts an election by sending RequestVote RPCs. Since it cannot reach the majority, it doesn’t become leader.
Meanwhile, the rest of the cluster still has a leader B. Because B can talk to a majority of servers, it continues to accept new log entries, replicate them, and safely commit them. Remember: in Raft, an entry is considered committed only after it is stored on a majority of servers.
Later, when connectivity is restored, server A now has a higher term than B. This causes A to reject AppendEntries from B, forcing B to step down. At this moment, no leader exists until a new election is held.
Here’s where Raft’s rules keep the system safe:
- A cannot win leadership election because its log is missing committed entries that the majority already agreed on. Other servers will refuse to vote for it by comparing their latest log index and term with
RequestVoteRPC Arg’sLastLogIndexandLastLogTerm. - A new leader must have logs that are at least as up-to-date as the majority. This ensures that committed entries are never lost.
- Once a new leader is elected, it brings A back in sync by replicating the missing committed entries.
This scenario highlights how Raft’s election rules preserve correctness: even if a partitioned follower returns with a higher term, it cannot override the majority’s progress. Leadership always ends up with a server that reflects all committed entries, and the cluster converges to the same state.
In upcoming parts, we’ll dive deeper into Raft’s log replication process and how heartbeats help keep leaders and followers synchronized.
Given below is the implementation for
RequestVotewhich highlights all the restrictions and responses for various election restrictions.
1func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
2 rf.mu.Lock()
3 defer rf.mu.Unlock()
4
5 fmt.Printf("[Peer: %d | RequestVote]: Candidate %d seeking vote for term: %d.\n", rf.me, args.CandidateId, args.Term)
6
7 // Election voting restrictions for follower
8 // - Candidate's term is older than follower from whom it is seeking vote
9 // - Follower already voted
10 // - Candidate's log is older then the follower
11 // In all the above cases follower will not vote for the candidate and respond back with its current term
12 // for the candidate to roll back to follower
13 isCandidateOfOlderTerm := args.Term < rf.currentTerm
14
15 if isCandidateOfOlderTerm {
16 reply.Term = rf.currentTerm
17 reply.VoteGranted = false
18
19 fmt.Printf("[Peer: %d | RequestVote]: Candidate %d is of older term. Candidate's term: %d | My current term %d\n", rf.me, args.CandidateId, args.Term, rf.currentTerm)
20
21 return
22 } else {
23 fmt.Printf("[Peer: %d | RequestVote]: Candidate %d is of newer or equal term. Candidate's term: %d | My current term %d\n", rf.me, args.CandidateId, args.Term, rf.currentTerm)
24
25 if args.Term > rf.currentTerm {
26 if rf.state == StateLeader {
27 fmt.Printf("[Peer: %d | RequestVote]: Recieved vote request from candiate of higher term, winding up my own leadership setup.\n", rf.me)
28 if rf.leaderCancelFunc != nil {
29 rf.leaderCancelFunc()
30 rf.replicatorCond.Broadcast()
31 }
32 }
33
34 rf.currentTerm = args.Term
35 rf.state = StateFollower
36 rf.votedFor = -1
37
38 rf.persist(nil)
39 }
40
41 canVote := rf.votedFor == -1 || rf.votedFor == args.CandidateId
42 var currentLatestLogTerm int
43 currentLatestLogIndex := len(rf.log) - 1
44
45 if currentLatestLogIndex > 0 {
46 currentLatestLogTerm = rf.log[currentLatestLogIndex].Term
47 } else if rf.snapshotLastLogIndex > 0 {
48 currentLatestLogTerm = rf.snapshotLastLogTerm
49 }
50
51 currentLatestLogIndex += rf.snapshotLastLogIndex
52
53 isCandidateLogOlder := args.LastLogTerm < currentLatestLogTerm || (args.LastLogTerm == currentLatestLogTerm && args.LastLogIndex < currentLatestLogIndex)
54
55 if canVote && !isCandidateLogOlder {
56 fmt.Printf("[Peer: %d | RequestVote]: Granted vote for term: %d, To candidate %d.\n", rf.me, args.Term, args.CandidateId)
57 rf.votedFor = args.CandidateId
58 rf.lastContactFromLeader = time.Now()
59
60 reply.VoteGranted = true
61 rf.persist(nil)
62 } else {
63 fmt.Printf("[Peer: %d | RequestVote]: Candidate %d log is older than mine. Log(index/term): Candidate's: (%d, %d) | Mine: (%d, %d).\n", rf.me, args.CandidateId, args.LastLogIndex, args.LastLogTerm, currentLatestLogIndex, currentLatestLogTerm)
64 reply.VoteGranted = false
65 }
66
67 reply.Term = rf.currentTerm
68 }
69}
Here are some things to keep in mind when implementing the RequestVote RPC:
- Note the use of
snapshotLastLogIndexandsnapshotLastLogTerm, which relate to log compaction. Think of a snapshot as capturing the current state machine’s image, allowing us to shorten logs up to that point, reducing overall log size. We’ll explore how this works and its benefits later. For now, understand that a server, when verifying if a candidate has current logs, needs to read its own. If the log is truncated shortly after a snapshot, we store the snapshot’s last details, like the index and term of the log at that index. Snapshotting generally shortens the log, but because indexes always increase, we usesnapshotLastLogIndexas an offset to get the right index. - When a candidate gets a majority, it calls
setupLeader, creating a context that can be cancelled, using Go’s context package. This context returns a function,leaderCancelFunc, which, when called, cancels the context. We do this when a leader steps down, such as when it receives aRequestVoteRPC from a candidate with a higher term. In this case, we cancel the leader’s context. This is useful when the leader is performing async operations (like sending heartbeats or logs) and waiting for them. We then wait for the operation to complete or the context to be cancelled, signalling that we no longer need to wait because the current server is no longer the leader. We’ll see what happens when a leader’s context is cancelled later. - A potentially confusing aspect is that when we receive a
RequestVoteRPC response denying the vote and containing a Term greater than our current one, we examine the candidate’s current state. This state might no longer be “candidate” because theRequestVoteRPC could be delayed, and the node might have already gained a majority and become the leader. Despite any RPC delays, we strictly adhere to a core Raft principle: upon receiving an RPC response with a Term greater than our current Term, we immediately update our Term to match the response. If we are the leader, we step down. This rule is crucial because the Term serves as a time indicator for the entire Raft cluster. Discovering that time has progressed requires us to adapt accordingly.
So to summarize:
When a follower receives a RequestVote, it rejects the request if:
- The candidate’s term is smaller (
args.Term < rf.currentTerm). - It has already voted for another candidate in this term (
rf.votedFor != -1 && rf.votedFor != args.CandidateId). - The candidate’s log is less up-to-date than its own, according to Raft’s freshness rule: Candidate’s last log term must be greater, or equal with a log index at least as large.
We have already seen how ticker calls startElection method based on election timeout, Let’s now understand with given below implementation of startElection, How a candidate asks for votes and what are the edge cases to consider while waiting for RequestVote RPC responses
1func (rf *Raft) startElection() {
2 rf.mu.Lock()
3
4 // Tigger election, send RequestVote RPC
5 // Once you have voted for someone in a term the elction timeout should be reset
6 // Reset election timer for self
7 rf.lastContactFromLeader = time.Now()
8
9 // Reset the election timeout with new value
10 rf.electionTimeout = time.Duration(1500+(rand.Int63()%1500)) * time.Millisecond
11 rf.currentTerm += 1 // increase term
12 rf.state = StateCandidate
13 peerCount := len(rf.peers)
14
15 voteCount := 1 // self vote
16 lastLogIndex := len(rf.log) - 1
17 var lastLogTerm int
18
19 done := make(chan struct{})
20
21 if lastLogIndex > 0 {
22 lastLogTerm = rf.log[lastLogIndex].Term
23 } else if rf.snapshotLastLogIndex > 0 {
24 lastLogTerm = rf.snapshotLastLogTerm
25 }
26
27 lastLogIndex += rf.snapshotLastLogIndex
28
29 rf.persist(nil)
30
31 fmt.Printf("[Candidate: %d | Election Ticker]: Election timout! Initiating election for term %d, with lastLogIndex: %d & lastLogTerm: %d.\n", rf.me, rf.currentTerm, lastLogIndex, lastLogTerm)
32 fmt.Printf("[Candidate: %d | Election Ticker]: Election timeout reset to: %v.\n", rf.me, rf.electionTimeout)
33
34 args := &RequestVoteArgs{
35 Term: rf.currentTerm,
36 CandidateId: rf.me,
37 LastLogIndex: lastLogIndex,
38 LastLogTerm: lastLogTerm,
39 }
40 requestVoteResponses := make(chan *RequestVoteReply)
41
42 for peerIndex, peer := range rf.peers {
43 if peerIndex != rf.me {
44 go func(peer *labrpc.ClientEnd) {
45 select {
46 case <-done:
47 // Either majority is achieved or candidate is stepping down as candidate
48 // Dont wait for this peer's RequestVote RPC response and exit this goroutine
49 // to prevent goroutine leak
50 return
51 default:
52 reply := &RequestVoteReply{}
53 fmt.Printf("[Candidate: %d | Election Ticker]: Requesting vote from peer: %d.\n", rf.me, peerIndex)
54 ok := peer.Call("Raft.RequestVote", args, reply)
55 if ok {
56 select {
57 case requestVoteResponses <- reply:
58 case <-done:
59 return
60 }
61 }
62 }
63 }(peer)
64 }
65 }
66
67 // Releasing the lock after making RPC calls
68 // Each RPC call for RequestVote is in its own thread so its not blocking
69 // We can release the lock after spawning RequestVote RPC thread for each peer
70 // Before releasing the lock lets make copy of some state to verify sanity
71 // After reacquiring the lock
72 electionTerm := rf.currentTerm
73 rf.mu.Unlock()
74
75 majority := peerCount/2 + 1
76
77 for i := 0; i < peerCount-1; i++ {
78 select {
79 case res := <-requestVoteResponses:
80 if rf.killed() {
81 fmt.Printf("[Candidate: %d | Election Ticker]: Candidate killed while waiting for peer RequestVote response. Aborting election process.\n", rf.me)
82 close(done) // Signal all other RequestVote goroutines to stop
83 return
84 }
85
86 rf.mu.Lock()
87
88 // State stale after RequestVote RPC
89 if rf.currentTerm != electionTerm || rf.state != StateCandidate {
90 rf.mu.Unlock()
91 close(done)
92 return
93 }
94
95 if res.Term > rf.currentTerm {
96 // A follower voted for someone else
97 // If they voted for same term then we can ignore
98 // But if term number is higher than our current term then
99 // we should step from candidate to follower and update our term as well
100 fmt.Printf("[Candidate: %d | Election Ticker]: Stepping down as Candidate, Recieved RequestVoteReply with term value %d > %d - my currentTerm.\n", rf.me, res.Term, rf.currentTerm)
101
102 rf.currentTerm = res.Term
103 rf.state = StateFollower
104 rf.mu.Unlock()
105
106 rf.persist(nil)
107 close(done)
108 return
109 }
110
111 if res.VoteGranted {
112 voteCount++
113 if voteCount >= majority {
114 // Won election
115 fmt.Printf("[Candidate: %d | Election Ticker]: Election won with %d/%d majority! New Leader:%d.\n", rf.me, voteCount, peerCount, rf.me)
116 rf.state = StateLeader
117
118 rf.mu.Unlock()
119 close(done)
120
121 rf.setupLeader()
122 return
123 }
124 }
125
126 rf.mu.Unlock()
127
128 case <-time.After(rf.electionTimeout):
129 rf.mu.Lock()
130 fmt.Printf("[Candidate: %d | Election Ticker]: Election timeout! Wrapping up election for term: %d. Got %d votes. Current state = %d. Current set term: %d.\n", rf.me, electionTerm, voteCount, rf.state, rf.currentTerm)
131 rf.mu.Unlock()
132
133 close(done)
134 return
135 }
136
137 }
138}
Within startElection, we construct RequestVoteArgs and concurrently dispatch the RPC to every peer using separate goroutines for each call. A done channel is also provided to these goroutines to signal events such as:
- Election cancellation, occurring if the Candidate reverts to Follower status, potentially after sending initial
RequestVoteRPCs upon receiving a heartbeat OR aRequestVoteRPC from another peer whose Term is at least the Candidate’s current Term. - Cancellation of waiting for
RequestVoteRPC responses if a majority has been secured or the election timeout is reached. - It’s worth noting that after sending RPC calls to each peer, we release the lock. This prevents us from blocking other incoming messages to that peer while awaiting RPC responses. This is why we use the
doneGo channel. It ensures that any concurrent request from elsewhere that modifies the candidate’s status is notified. This happens when thedonechannel is closed, causing thecase <-done:statement to return first in theselectblock.
6.5840 Labs provide us with following test cases for leader election:
1❯ go test -run 3A
2Test (3A): initial election (reliable network)...
3 ... Passed -- time 5.5s #peers 3 #RPCs 36 #Ops 0
4Test (3A): election after network failure (reliable network)...
5 ... Passed -- time 8.4s #peers 3 #RPCs 50 #Ops 0
6Test (3A): multiple elections (reliable network)...
7 ... Passed -- time 16.9s #peers 7 #RPCs 382 #Ops 0
8PASS
9ok 6.5840/raft1 31.352s
Conclusion
In this part we understood how RAFT manages a replicated log across a cluster of machines, ensuring consistency and availability. The post details the roles of leader, follower, and candidate, along with the key concepts of terms, log entries, leader election, and log replication. Crucial mechanisms, such as checks on RequestVote and AppendEntries RPCs and random timeouts, guarantee leader accuracy and prevent split votes. The post lays the groundwork for understanding how RAFT ensures that committed log entries are never lost and how a valid leader is reliably elected.
In subsequent parts, we will see how we set up a leader when a candidate wins election and how we handle leader stepping down from leadership. Then we will see how log replication actually happens along with cases of log conflicts and log corrections by leader and how heartbeats helps to achieve that, In the end we will trace a client request to see the behaviour of this distributed cluster seen as a single machine from client’s point of view.