We previously discussed replicated state machines, leader election in the RAFT consensus algorithm, and log-based state maintenance. Now, we’ll focus on log replication across peer servers. We’ll also examine how RAFT ensures that the same commands are applied to the state machine at a given log index on every peer, because of the leader’s one-way log distribution to followers.
Leader Initialisation
Once a candidate becomes leader we call setupLeader function which initiates go routine for each peer in the RAFT cluster, Each go routine of respective peer is responsible for replicating new log entries or sending heartbeat via AppendEntries RPC.
1func (rf *Raft) setupLeader() {
2 rf.mu.Lock()
3 defer rf.mu.Unlock()
4
5 ctx, cancel := context.WithCancel(context.Background())
6 rf.leaderCancelFunc = cancel
7
8 for peerIndex := range rf.peers {
9 if peerIndex != rf.me {
10 rf.nextIndex[peerIndex] = len(rf.log) + rf.snapshotLastLogIndex
11 go rf.replicate(peerIndex, ctx)
12 }
13 }
14
15 go func() {
16 for !rf.killed() {
17 select {
18 case <-ctx.Done():
19 return
20 case <-time.After(HEARTBEAT_TIMEOUT):
21 rf.replicatorCond.Broadcast()
22 }
23 }
24 }()
25}
When starting a replication logic thread for each peer, we also send a Go context to rf.replicate. This context shows the current leader’s status. If the leader steps down, we call rf.leaderCancelFunc, which cancels the context. When a context is canceled, the ctx.Done() channel closes, stopping any waiting for results from that channel. More information about Go’s context can be found here.
Our RAFT struct includes a condition variable, replicatorCond (of type *sync.Cond), that signals all peer goroutines of the leader to run the replication logic every HEARTBEAT_TIMEOUT. This ensures that a heartbeat is sent to each peer at the specified interval.
A condition variable provides functions like Wait, Signal, and Broadcast. If multiple threads are waiting on a condition variable after releasing the underlying mutex, Signal will wake one of such waiting threads, and Broadcast will wake all waiting threads. Here we are using Broadcast to wake all waiting threads of each peer to send the next heartbeat. A condition variable is an operating system concept, and you can read more about the same from here. To read about the API of Go’s of type *sync.Cond, check Go’s official Docs here.
Log Replication
Each individual peer thread runs the replicate method, given below is implementation of rf.replicate function
1func (rf *Raft) replicate(peerIndex int, ctx context.Context) {
2 logMismatch := false
3 for !rf.killed() {
4 select {
5 case <-ctx.Done():
6 dprintf("[leader-replicate: %d | peer: %d]: Leader stepped down from leadership before initiating replicate.\n", rf.me, peerIndex)
7 return
8 default:
9 rf.mu.Lock()
10
11 if rf.state != StateLeader {
12 dprintf("[leader-replicate: %d | peer: %d]: Not a leader anymore, winding up my leadership setup.\n", rf.me, peerIndex)
13 if rf.leaderCancelFunc != nil {
14 rf.leaderCancelFunc()
15 rf.replicatorCond.Broadcast()
16 }
17 rf.mu.Unlock()
18 return
19 }
20
21 // Only waiting when:
22 // - There is no log to send - In this case the wait will be signalled by the heartbeat
23 // - We are in a continuous loop to find correct nextIndex for this peer with retrial RPCs
24 if !logMismatch && rf.nextIndex[peerIndex] >= len(rf.log)+rf.snapshotLastLogIndex {
25 dprintf("[leader-replicate: %d | peer: %d]: Wating for next signal to replicate.\n", rf.me, peerIndex)
26 rf.replicatorCond.Wait()
27 }
28
29 if rf.killed() {
30 return
31 }
32
33 reply := &AppendEntriesReply{}
34 logStartIndex := rf.nextIndex[peerIndex]
35 var prevLogTerm int
36 prevLogIndex := logStartIndex - 1
37 peer := rf.peers[peerIndex]
38
39 if prevLogIndex-rf.snapshotLastLogIndex > 0 {
40 prevLogTerm = rf.log[prevLogIndex-rf.snapshotLastLogIndex].Term
41 } else if prevLogIndex == rf.snapshotLastLogIndex {
42 prevLogTerm = rf.snapshotLastLogTerm
43 } else {
44 // prevLogIndex < rf.snapshotLastLogIndex
45 prevLogTerm = -1
46 }
47
48 if prevLogTerm == -1 {
49 logMismatch = true
50 // Leader does not have logs at `prevLogIndex` because of compaction
51 // Leader needs to send snaphot to the peer as part of log repairing
52 args := &InstallSnapshotArgs{
53 Term: rf.currentTerm,
54 LeaderId: rf.me,
55 LastIncludedIndex: rf.snapshotLastLogIndex,
56 LastIncludedTerm: rf.snapshotLastLogTerm,
57 Data: rf.persister.ReadSnapshot(),
58 }
59
60 reply := &InstallSnapshotReply{}
61
62 dprintf("[leader-install-snapshot: %d: peer: %d]: InstallSnapshot RPC with index: %d and term: %d sent.\n", rf.me, peerIndex, args.LastIncludedIndex, args.LastIncludedTerm)
63 rf.mu.Unlock()
64
65 ok := rf.sendRPCWithTimeout(ctx, peer, peerIndex, "InstallSnapshot", args, reply)
66
67 rf.mu.Lock()
68
69 if ok {
70 if reply.Term > rf.currentTerm {
71 dprintf("[leader-install-snapshot: %d: peer: %d]: Stepping down from leadership, Received InstallSnapshot reply from peer %d, with term %d > %d - my term\n", rf.me, peerIndex, peerIndex, reply.Term, rf.currentTerm)
72
73 rf.state = StateFollower
74 rf.currentTerm = reply.Term
75 rf.lastContactFromLeader = time.Now()
76
77 if rf.leaderCancelFunc != nil {
78 rf.leaderCancelFunc()
79 rf.replicatorCond.Broadcast()
80 }
81 rf.persist(nil)
82 rf.mu.Unlock()
83 return
84 }
85
86 dprintf("[leader-install-snapshot: %d: peer: %d]: Snapshot installed successfully\n", rf.me, peerIndex)
87 rf.nextIndex[peerIndex] = rf.snapshotLastLogIndex + 1
88 rf.mu.Unlock()
89 continue
90 } else {
91 dprintf("[leader-install-snapshot: %d: peer: %d]: Snapshot installtion failed!\n", rf.me, peerIndex)
92 rf.nextIndex[peerIndex] = rf.snapshotLastLogIndex
93 rf.mu.Unlock()
94 continue
95 }
96 } else {
97 replicateTerm := rf.currentTerm
98
99 logEndIndex := len(rf.log) + rf.snapshotLastLogIndex
100 nLogs := logEndIndex - logStartIndex
101
102 args := &AppendEntriesArgs{
103 Term: rf.currentTerm,
104 LeaderId: rf.me,
105 PrevLogIndex: prevLogIndex,
106 PrevLogTerm: prevLogTerm,
107 LeaderCommit: rf.commitIndex,
108 }
109
110 if nLogs > 0 {
111 entriesToSend := rf.log[logStartIndex-rf.snapshotLastLogIndex:]
112 args.Entries = make([]LogEntry, len(entriesToSend))
113 copy(args.Entries, entriesToSend)
114 dprintf("[leader-replicate: %d | peer: %d]: Sending AppendEntries RPC in term %d with log index range [%d, %d).\n", rf.me, peerIndex, replicateTerm, logStartIndex, logEndIndex)
115 } else {
116 dprintf("[leader-replicate: %d | peer: %d]: Sending AppendEntries Heartbeat RPC for term %d.\n", rf.me, peerIndex, replicateTerm)
117 }
118
119 rf.mu.Unlock()
120 ok := rf.sendRPCWithTimeout(ctx, peer, peerIndex, "AppendEntries", args, reply)
121
122 rf.mu.Lock()
123
124 if ok {
125 select {
126 case <-ctx.Done():
127 dprintf("[leader-replicate: %d | peer: %d]: Leader stepped down from leadership after sending AppendEntries RPC.\n", rf.me, peerIndex)
128 rf.mu.Unlock()
129 return
130 default:
131 // Check fot change in state during the RPC call
132 if rf.currentTerm != replicateTerm || rf.state != StateLeader {
133 // Leader already stepped down
134 dprintf("[leader-replicate: %d | peer: %d]: Checked ladership state after getting AppendEntries Reply, Not a leader anymore, Winding up my leadership setup.\n", rf.me, peerIndex)
135 if rf.leaderCancelFunc != nil {
136 rf.leaderCancelFunc()
137 rf.replicatorCond.Broadcast()
138 }
139 rf.mu.Unlock()
140 return
141 }
142
143 // Handle Heartbeat response
144 if !reply.Success {
145 if reply.Term > rf.currentTerm {
146 dprintf("[leader-replicate: %d: peer: %d]: Stepping down from leadership, Received ApppendEntries reply from peer %d, with term %d > %d - my term\n", rf.me, peerIndex, peerIndex, reply.Term, rf.currentTerm)
147
148 rf.state = StateFollower
149 rf.currentTerm = reply.Term
150 rf.lastContactFromLeader = time.Now()
151
152 if rf.leaderCancelFunc != nil {
153 rf.leaderCancelFunc()
154 rf.replicatorCond.Broadcast()
155 }
156 rf.persist(nil)
157 rf.mu.Unlock()
158 return
159 }
160
161 // Follower rejected the AppendEntries RPC beacuse of log conflict
162 // Update the nextIndex for this follower
163 logMismatch = true
164 followersConflictTermPresent := false
165 if reply.ConflictTerm != -1 {
166 for i := prevLogIndex - rf.snapshotLastLogIndex; i > 0; i-- {
167 if rf.log[i].Term == reply.ConflictTerm {
168 rf.nextIndex[peerIndex] = i + 1 + rf.snapshotLastLogIndex
169 followersConflictTermPresent = true
170 break
171 }
172
173 }
174
175 if !followersConflictTermPresent {
176 rf.nextIndex[peerIndex] = reply.ConflictIndex
177 }
178 } else {
179 rf.nextIndex[peerIndex] = reply.ConflictIndex
180 }
181 dprintf("[leader-replicate: %d | peer: %d]: Logmismatch - AppendEntries RPC with previous log index %d of previous log term %d failed. Retrying with log index:%d.\n", rf.me, peerIndex, prevLogIndex, prevLogTerm, rf.nextIndex[peerIndex])
182 rf.mu.Unlock()
183 continue
184 } else {
185 dprintf("[leader-replicate: %d | peer: %d]: responded success to AppendEntries RPC in term %d with log index range [%d, %d).\n", rf.me, peerIndex, replicateTerm, logStartIndex, logEndIndex)
186 logMismatch = false
187
188 if nLogs > 0 {
189 // Log replication successful
190 rf.nextIndex[peerIndex] = prevLogIndex + nLogs + 1
191 rf.matchIndex[peerIndex] = prevLogIndex + nLogs
192
193 // Need to track majority replication upto latest log index
194 // - So that we can update commitIndex
195 // - Apply logs upto commitIndex
196 // Just an idea - maybe this needs to be done separately in a goroutine
197 // Where we continuosly check lastApplied and commitIndex
198 // Apply and lastApplied to commit index and if leader send the response to apply channel
199 majority := len(rf.peers)/2 + 1
200
201 for i := len(rf.log) - 1; i > rf.commitIndex-rf.snapshotLastLogIndex; i-- {
202 matchedPeerCount := 1
203 if rf.log[i].Term == rf.currentTerm {
204 for pi := range rf.peers {
205 if pi != rf.me && rf.matchIndex[pi] >= i+rf.snapshotLastLogIndex {
206 matchedPeerCount++
207 }
208 }
209 }
210
211 // Largest possible log index greater the commitIndex replicated at majority of peers
212 // update commitIndex
213 if matchedPeerCount >= majority {
214 rf.commitIndex = i + rf.snapshotLastLogIndex
215
216 dprintf("[leader-replicate: %d | peer: %d]: Log index %d replicated to majority of peers.(%d/%d peers), updating commitIndex to : %d, current lastApplied value: %d.\n", rf.me, peerIndex, i+rf.snapshotLastLogIndex, matchedPeerCount, len(rf.peers), rf.commitIndex, rf.lastApplied)
217 rf.applyCond.Signal()
218 break
219 }
220 }
221 }
222
223 rf.mu.Unlock()
224 continue
225 }
226 }
227 }
228 dprintf("[leader-replicate: %d | peer %d]: Sending AppendEntries RPC at leader's term: %d, failed. Payload prevLogIndex: %d | prevLogTerm: %d.\n", rf.me, peerIndex, replicateTerm, prevLogIndex, prevLogTerm)
229 rf.mu.Unlock()
230 continue
231 }
232 }
233 }
234}
The replicate function operates in a continuous loop. Inside this loop, a select statement monitors the leader’s context (ctx) status. If ctx.Done() is not yet closed, it confirms the current server is still the leader. To ensure correctness, the server’s current state is also checked to be StateLeader. If it’s not, rf.leaderCanelFunc is explicitly called to relinquish leadership, which closes the context’s done channel, signalling the leader’s relinquishment to other components. Additionally, the loop waits on rf.replicatorCond when there are no more logs to transmit and no log mismatch between the leader’s and the peer’s logs.
As mentioned in Part 1 of this blog series, servers periodically compact their logs to manage their size. This involves taking a snapshot of the current state and then truncating the log up to that point. If a follower’s log is significantly behind the leader’s and the leader has already truncated its log, the leader may need to send a snapshot using the InstallSnapshot RPC. We will delve deeper into log compaction in a later part of this series.
Leader maintains volatile state for each peer nextIndex and matchIndex, these two properties for each peer are maintained by the leader, and it tells the leader which next log index to send to the peer and index up to which logs are replicated for that peer respectively.
Heartbeat rules
The AppendEntries RPC also functions as a heartbeat, allowing the leader to communicate its identity and log status to all followers. A follower only accepts this RPC if:
- The leader’s
Termvalue is greater than or equal to the follower’s current term. If not, the follower rejects the RPC, signalling that the sender (mistakenly believing itself to be the leader) is outdated. The follower sends its ownreply.Termto indicate this. Upon receiving aTermin the reply that is higher than its own, the leader relinquishes leadership. - The leader includes
PrevLogIndexandPrevLogTermwith eachAppendEntriesRPC. These values are vital, as they indicate the leader’s log state by specifying the index and term of the log up to which the leader believes the follower’s log matches. If there is a discrepancy, the follower responds withreply.Successset to false, indicating a log mismatch. The leader then decreasesnextIndex[peerIndex]for that peer and sends another heartbeat with an earlier log index. This process continues until a matching log index is found. At that point, the follower accepts the leader’sAppendEntriesRPC and uses thereconcileLogsfunction to remove conflicting log entries and replace them with the log range sent by the leader from[PrevLogIndex + 1, LatestLogIndexAtLeader]. extracted fromargs,Entriesfield. This RAFT property is followed by each index of the follower, so if the current index and term match with the leader, so does the log index previous to this one, or else a conflict would have occurred previously itself. So this single property ensures that the log state matches between leader and follower up to the latest index; otherwise, the follower will not accept the heartbeat or normalAppendEntriesRPC with log entries, and the to-and-fro of heartbeats after that to find the non-conflict index at the follower is called the log correction process. Later on, we will see how we can optimise this log correction because currently the leader needs to try for each log index in decreasing order, which can take a lot of time if the follower has been stale for a long time and during that time the leader’s log has grown a lot.
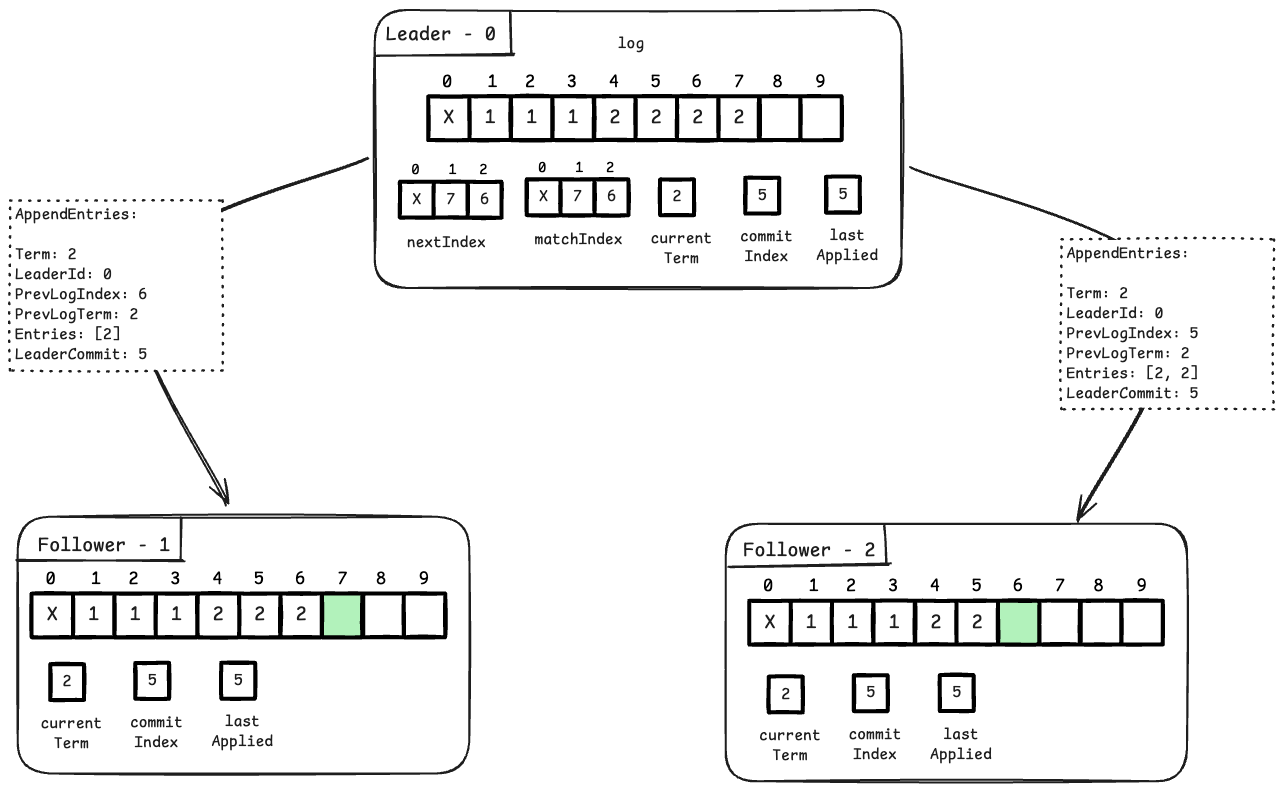 The image above, shows a simple successful log replication situation. Here, Follower 1 and Follower 2 have the same initial part of the log as the leader. Also, the leader knows exactly which parts of the log need to be sent to each follower.
The image above, shows a simple successful log replication situation. Here, Follower 1 and Follower 2 have the same initial part of the log as the leader. Also, the leader knows exactly which parts of the log need to be sent to each follower.
In the replicate method, we use a logMismatch flag within the replication loop. This flag shows if there was a log problem when sending the AppendEntries RPC in the last loop. If there was a problem, we don’t wait (we don’t call rf.replicatorCond.Wait(), which releases the lock and puts the thread to sleep). This is because, if there’s a log problem, we want to fix the log quickly, so we send the next AppendEntries RPC right away with the updated previous log index and term.
If the previous log index is less than the index up to which we’ve taken a snapshot of the state and shortened the log, we send an InstallSnapshot RPC to send the snapshot to the follower instead, since we don’t have the needed logs. We’ll discuss snapshots and log compaction more later.
We still follow one rule closely: if we get an RPC reply with a term value higher than the leader’s current term, the leader gives up leadership by cancelling the context. See the previous part for more information.
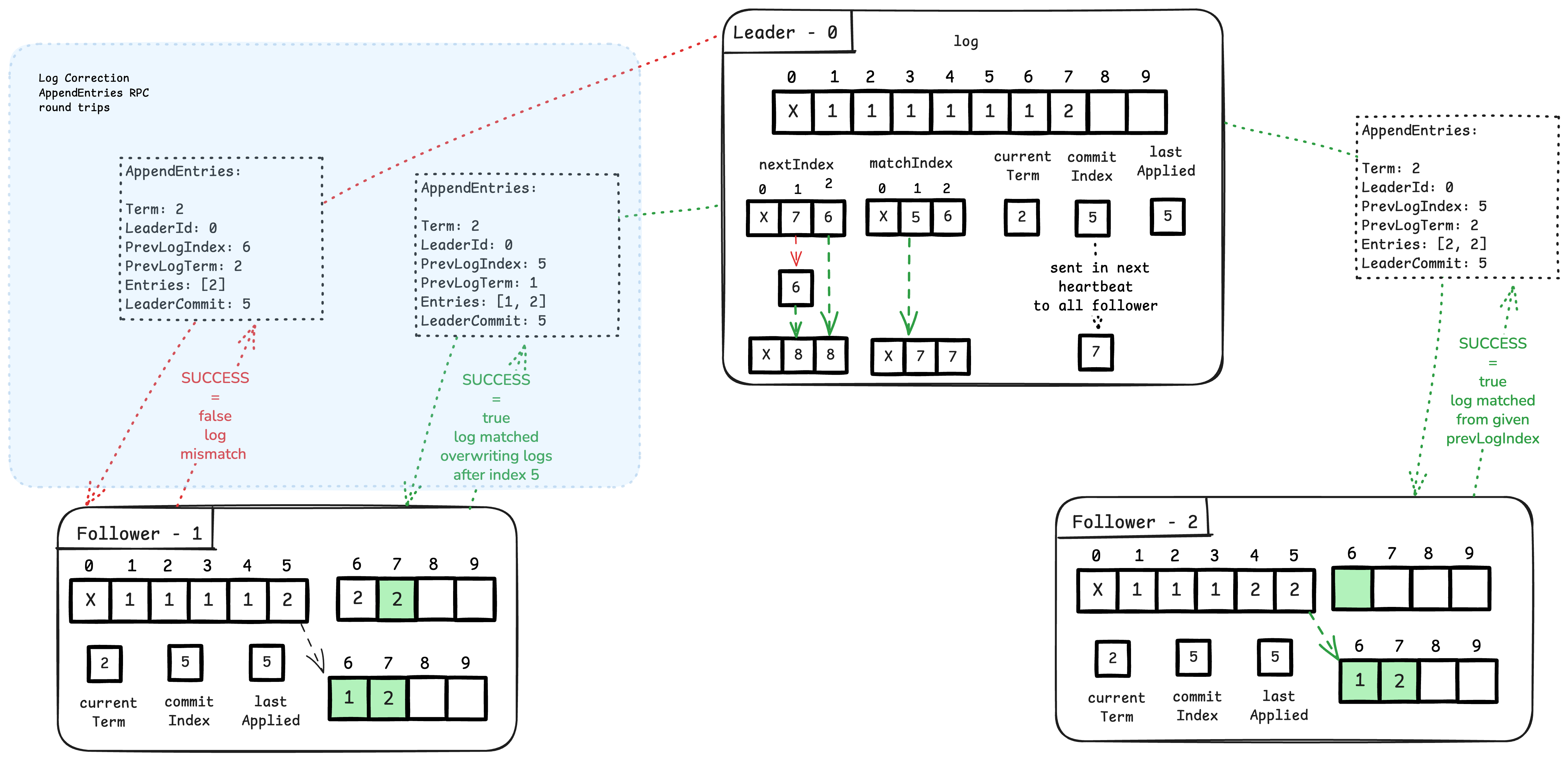 In the image, follower 1’s
In the image, follower 1’s nextIndex is at index 7. When an AppendEntries RPC is sent with prevLogIndex=6 and prevLogTerm=2, the follower detects a log mismatch and rejects the RPC. Because the follower’s term is also 2, the leader keeps its leadership role and immediately reduces its nextIndex for follower 1 to 6. It then sends another AppendEntries RPC (without waiting due to logMismatch=true) with prevLogIndex=5 and prevLogTerm=2. This second RPC is accepted. The leader sends Entries=[1, 2], causing the entries after index 5 to be replaced by these new entries (handled by ). Thus, the leader can erase uncommitted entries from the follower during log correction.
Follower 2 accepts the initial AppendEntries RPC because there is no conflict. Since The leader manages each peer in its own separate goroutine, After each successful RPC response, the leader checks if a majority (replication factor) has replicated the log up to a specific index. In this scenario, once follower 2 responds (likely before follower 1, which is still correcting its log), the leader will have replicated log index 7 on 2/3 of the peers (including itself).
The leader then updates its commitIndex and signals a condition variable called rf.applyCond. First, we will examine how the follower handles the AppendEntries RPC. Then, building on this understanding, we will discuss commitIndex, lastApplied, and rf.applyCond, explaining how they ensure log entries are committed, what “committed” means, what “applying” a log means, and how it is handled."
Handling AppendEntries RPC
Lets now look at how a Follower handles an AppendEntries RPC from a leader, we will revisit leader’s replicate method when we get to how logs are committed and applied to the state machine by the leader and how this change is propagated to followers.
Given below is the implementation of AppendEntries RPC:
1func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
2 // Handling heart beats from leader
3 // When follower recieves heartbeat it should check for heartbeat validity
4
5 // [Case: 1] if args.Term < rf.currentTerm then it means this follower is either a new leader
6 // OR it voted for someone else after least heartbeat.
7 // In such case follower should return reply.Success = false indicating it does not acknowledge the sender
8 // as leader anymore and should set reply.Term = rf.currentTerm. (This indicated sender to step down from leadership)
9
10 // [Case: 2] if args.Term >= rf.currentTerm the the current follower/candidate becomes follower again accepting current leader
11 // In such case rf.currentTerm = args.Term and reply.Success = true with reply.Term = rf.currentTerm (same term as the sender)
12 // In Case 2 we should reset the election timer since we have received the heartbeat from a genuine leader
13
14 // In Case 1 since the previous leader is now left behind, there are 3 possibilities:
15 // A. The current peer is a candidate now and an election was already started by it or even finished with it being the current leader
16 // B. Some other peer is now a candidate with an election going on OR is a leader now
17 // C. No election has taken place till now
18 // In all the above cases we should not interrupt the election timeout or anything else
19
20 rf.mu.Lock()
21 defer rf.mu.Unlock()
22
23 if len(args.Entries) == 0 {
24 // Heartbeat
25 dprintf("[Peer: %d]: Recieved AppendEntries RPC as heartbeat from leader %d for term %d with commitIndex %d.\n", rf.me, args.LeaderId, args.Term, args.LeaderCommit)
26 }
27
28 if args.Term < rf.currentTerm {
29 dprintf("[Peer: %d]: AppendEntries RPC from leader %d for term %d not acknowledged, Leader's term: %d is older than my current term: %d.\n", rf.me, args.LeaderId, args.Term, args.Term, rf.currentTerm)
30 reply.Success = false
31 reply.Term = rf.currentTerm
32
33 return
34 } else {
35 // Sent by current leader
36 // Reset election timeout
37 if rf.state == StateLeader {
38 dprintf("[Peer: %d]: AppendEntries RPC recieved from current leader: %d, winding up my leadership setup.\n", rf.me, args.LeaderId)
39 if rf.leaderCancelFunc != nil {
40 rf.leaderCancelFunc()
41 rf.replicatorCond.Broadcast()
42 }
43 }
44
45 rf.lastContactFromLeader = time.Now()
46
47 rf.currentTerm = args.Term
48 rf.state = StateFollower
49
50 rf.persist(nil)
51
52 latestLogIndex := len(rf.log) - 1
53 logTerm := 0
54
55 if args.PrevLogIndex > rf.snapshotLastLogIndex && args.PrevLogIndex <= latestLogIndex+rf.snapshotLastLogIndex {
56 logTerm = rf.log[args.PrevLogIndex-rf.snapshotLastLogIndex].Term
57 } else if args.PrevLogIndex == rf.snapshotLastLogIndex {
58 logTerm = rf.snapshotLastLogTerm
59 } else if args.PrevLogIndex < rf.snapshotLastLogIndex {
60 // This should trigger InstallSnapshot from leader
61 reply.ConflictIndex = rf.snapshotLastLogIndex + 1
62 reply.ConflictTerm = -1
63 }
64
65 if logTerm != args.PrevLogTerm {
66 dprintf("[Peer: %d]: AppendEntries RPC from leader %d for term %d not acknowledged. Log terms do not match, (Leader term, Leader index): (%d, %d), peer's term for same log index: %d.\n", rf.me, args.LeaderId, args.Term, args.PrevLogTerm, args.PrevLogIndex, logTerm)
67 reply.Success = false
68 reply.Term = rf.currentTerm
69
70 if args.PrevLogIndex <= latestLogIndex+rf.snapshotLastLogIndex {
71 reply.ConflictTerm = logTerm
72 i := args.PrevLogIndex - rf.snapshotLastLogIndex
73 // Find fist index of `logTerm` in follower's log
74 for ; i > 0; i-- {
75 if rf.log[i].Term != logTerm {
76 break
77 }
78 }
79
80 reply.ConflictIndex = i + 1 + rf.snapshotLastLogIndex
81 }
82
83 return
84 }
85
86 reply.Success = true
87 reply.Term = rf.currentTerm
88
89 dprintf("[Peer: %d]: AppendEntries RPC from leader %d for term %d acknowledged.\n", rf.me, args.LeaderId, args.Term)
90
91 if len(args.Entries) > 0 {
92 rf.reconcileLogs(args.Entries, args.PrevLogIndex)
93 }
94
95 if args.LeaderCommit > rf.commitIndex {
96 // If leaderCommit > commitIndex, set commitIndex =
97 // min(leaderCommit, index of last new entry)
98
99 rf.commitIndex = args.LeaderCommit
100
101 if args.LeaderCommit >= len(rf.log)+rf.snapshotLastLogIndex {
102 rf.commitIndex = len(rf.log) - 1 + rf.snapshotLastLogIndex
103 }
104
105 dprintf("[Peer: %d]: Updated commmit index to %d.\n", rf.me, rf.commitIndex)
106
107 rf.applyCond.Signal()
108 }
109 }
110
111}
Like other Remote Procedure Calls, we initially verify if the sender’s args.Term is lower than the recipient’s term. If it is, we reject the call, notifying the sending leader that its leadership is outdated and the cluster’s term has advanced since it was last the leader. We include the term value in the response, prompting the sender to relinquish leadership and begin synchronizing. As mentioned before, this synchronization occurs when the peer receives a heartbeat from the current leader, initiating any necessary log corrections. This demonstrates that log flow consistently originates from the current leader to all other followers.
The same principle applies if the receiving peer believes itself to be the leader of a term less than or equal to the term in the AppendEntries RPC. In this scenario, we acknowledge the sender as the rightful current leader and invoke rf.leaderCancelFunc() to force the current peer to step down from leadership. Additionally, we broadcast on rf.replicatorCond to ensure that all peer-specific replication threads spawned by this receiver recognize the effect of the cancelled context as quickly as possible.
After confirming the leader’s identity, we begin by updating the lastContactFromLeader timestamp. Each follower has a ticker that verifies if the last communication from the leader exceeded a set threshold (the election timeout). If it does, the follower can become a candidate and initiate an election. Updating the timestamp prevents unnecessary elections. More information about leader election can be found in the preceding section.
After this We move on to verifying log consistency. This is done using the PrevLogIndex and PrevLogTerm fields of the AppendEntries RPC.
The follower checks if it has a log entry at PrevLogIndex and whether that entry’s term matches PrevLogTerm. If either of these checks fail, it indicates that the follower’s log has diverged from the leader’s. In such cases, the follower rejects the RPC by returning Success = false. This rejection signals to the leader that it needs to adjust its nextIndex for this follower and retry from an earlier point in its log, Effectively “backing up” until it finds the last matching entry.
Now, without any optimization, this correction process could be quite inefficient: the leader would decrement nextIndex[peer] one step at a time and re-send the RPC repeatedly until it finds a match. If the follower has fallen far behind (say, by N entries), this would take N separate RPCs: a linear-time process that can become costly in large logs.
To avoid that, Raft introduces a log inconsistency optimization. Instead of merely rejecting the RPC, the follower includes two additional fields in its response: ConflictTerm and ConflictIndex. These tell the leader the term of the conflicting entry and the first index where that term begins.
With this information, the leader can skip behind intelligently. It looks for the last entry in its own log with the same ConflictTerm.
- If it finds one, it sets the follower’s
nextIndexto just after that entry: meaning it assumes both logs agree up to that point, This assumption may fail when theAppendEntriesis again rejected with backed upnextIndexvalue which means the followers log are lagging behind leader’s term at that index, so leader will repeat this process again with newConflictIndexandConflictTerm - If it doesn’t find any entry with that term, it sets
nextIndextoConflictIndex, effectively jumping back to where the follower’s conflicting term started. This optimization allows the leader to perform correction per term, rather than per index, drastically reducing the number of RPCs needed for log repair, especially when followers lag by many entries. You can check the code forreplicatemethod above (especially when theres.Successis set to false withres.Term <= leader.currentTerm)to check the above behaviour of leader during log conflict. Once a consistent prefix is identified, the follower can safely append new entries included in the RPC. In the implementation, this is handled by thereconcileLogsmethod, which takes the leader’s entries and merges them into the follower’s log while ensuring term consistency.
1func (rf *Raft) reconcileLogs(leaderEntries []LogEntry, leaderPrevLogIndex int) {
2 nextIndex := leaderPrevLogIndex + 1
3 currentLogLength := len(rf.log) + rf.snapshotLastLogIndex
4 leaderEntriesIndex := 0
5
6 for nextIndex < currentLogLength && leaderEntriesIndex < len(leaderEntries) {
7 if rf.log[nextIndex-rf.snapshotLastLogIndex].Term != leaderEntries[leaderEntriesIndex].Term {
8 break
9 }
10
11 nextIndex++
12 leaderEntriesIndex++
13 }
14
15 if leaderEntriesIndex < len(leaderEntries) {
16 // If an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it
17 rf.log = rf.log[:nextIndex-rf.snapshotLastLogIndex]
18
19 // Append any new entries not already in the log
20 rf.log = append(rf.log, leaderEntries[leaderEntriesIndex:]...)
21
22 rf.persist(nil)
23 }
24
25 dprintf("[Peer %d]: Reconciled logs with leader from index %d, current logs length %d.\n", rf.me, leaderPrevLogIndex, len(rf.log)+rf.snapshotLastLogIndex)
26}
This function essentially performs the final step of log reconciliation after the agreement point between leader and follower has been established.
- It starts from the index immediately after
leaderPrevLogIndex: the point up to which both leader and follower agree. - Then it walks through both logs in parallel, comparing terms for each entry.
- As soon as it finds a mismatch (a conflict in term at the same index), it stops: that’s where the logs diverge.
- From that point onward, it truncates the follower’s log (
rf.log = rf.log[:nextIndex - rf.snapshotLastLogIndex]) and appends all remaining entries from the leader’s log.
This effectively overwrites any inconsistent or “stale” entries on the follower with the authoritative entries from the leader, restoring complete log alignment.
So, reconcileLogs is the place where the follower’s log is actually modified. It’s where the “diff” from the leader is applied after the last point of agreement. Once again, this highlights the fundamental directionality of Raft’s replication flow: log entries always move from the leader to the followers, never the other way around.
Committing and Applying Log Entries
If a leader receives successful AppendEntries RPC responses from a majority of followers, it indicates that the logs of a majority of peers match the leader’s up to a specific index. Because agreement on a current log index implies agreement on all preceding indices, the leader can confidently assert that the logs match up to that given index. Consequently, the leader will then designate that index as the commit index.
1for i := len(rf.log) - 1; i > rf.commitIndex-rf.snapshotLastLogIndex; i-- {
2 matchedPeerCount := 1
3 if rf.log[i].Term == rf.currentTerm {
4 for pi := range rf.peers {
5 if pi != rf.me && rf.matchIndex[pi] >= i+rf.snapshotLastLogIndex {
6 matchedPeerCount++
7 }
8 }
9 }
10
11 // Largest possible log index greater the commitIndex replicated at majority of peers
12 // update commitIndex
13 if matchedPeerCount >= majority {
14 rf.commitIndex = i + rf.snapshotLastLogIndex
15
16 dprintf("[leader-replicate: %d | peer: %d]: Log index %d replicated to majority of peers.(%d/%d peers), updating commitIndex to : %d, current lastApplied value: %d.\n", rf.me, peerIndex, i+rf.snapshotLastLogIndex, matchedPeerCount, len(rf.peers), rf.commitIndex, rf.lastApplied)
17 rf.applyCond.Signal()
18 break
19 }
20}
This is evident at the end of the replicate method. After obtaining a success response for each peer-specific thread, the method verifies the matchIndex for all peers. Similar to nextIndex, each leader maintains a matchIndex for each peer. This matchIndex essentially signifies the index up to which the peer’s log matches the leader’s, or, in other words, the extent to which the leader’s log has been replicated to that follower.
As you can see if a new log entry has been replicated to majority, We also signal on applyCond condition variable.
Upon starting, each peer launches both a ticker go routine and an applier go routine. The applier’s function is to retrieve logs from the lastAppliedIndex (the point of the last application) up to the most recent commit index and execute each command on the state machine. In this setup, every Raft server instance receives an apply channel at startup, provided by the service utilizing RAFT. In our key-value server example, commands from log entries sent to the apply channel are processed by the KV server, which then executes them.
1func (rf *Raft) applier() {
2 for !rf.killed() {
3 rf.mu.Lock()
4 for rf.lastApplied >= rf.commitIndex {
5 rf.applyCond.Wait()
6 }
7
8 if rf.killed() {
9 return
10 }
11
12 i := rf.lastApplied + 1
13 if i < rf.snapshotLastLogIndex+1 {
14 i = rf.snapshotLastLogIndex + 1
15 }
16
17 messages := make([]raftapi.ApplyMsg, 0)
18 for ; i <= rf.commitIndex; i++ {
19 // Skip entries that are already in the snapshot
20 if i <= rf.snapshotLastLogIndex {
21 continue
22 }
23 msg := raftapi.ApplyMsg{
24 CommandValid: true,
25 Command: rf.log[i-rf.snapshotLastLogIndex].Command,
26 CommandIndex: i,
27 }
28 messages = append(messages, msg)
29 }
30 commitIndex := rf.commitIndex
31 rf.mu.Unlock()
32
33 for _, msg := range messages {
34 if rf.killed() {
35 return
36 }
37 rf.applyCh <- msg
38 }
39
40 rf.mu.Lock()
41 rf.lastApplied = commitIndex
42 dprintf("[Peer: %d]: Applied logs till latest commit index: %d, lastApplied : %d.\n", rf.me, rf.lastApplied, rf.commitIndex)
43 rf.mu.Unlock()
44 }
45}
While sending something to a Go channel, the channel itself can work concurrently with multiple threads pushing data from it. So, we do not need the
rf.mulock while sending commands, which can be a blocking operation. In a non-buffered channel, an inserted element is only accepted when there is an active consumer to consume that element. Therefore, to avoid holding the Raft server state’s lockmu, we release the lock and only reacquire it after we have applied all the logs to log out the Raft server’s state.
If the commitIndex is not greater than lastAppliedIndex, the applier thread pauses by unlocking and waiting for a signal. When the commitIndex of a leader or follower changes, the applier thread is signaled to resume and apply new logs (between lastAppliedIndex and commitIndex) to the state machine. The leader’s commitIndex is updated upon majority replication. To ensure the replicated state of follower matches the leader’s RAFT state (same commitIndex) and the underlying state machine’s state (e.g., the KV server’s state), the updated commitIndex of leader is included in the next upcoming AppendEntries RPC heartbeat. Each follower, after agreeing with the RPC, updates its own commitIndex and signals its applier thread to update the state machine with the new logs received from the leader.
1func (rf *Raft) (args *AppendEntriesArgs, reply *AppendEntriesReply) {
2// ...existing code
3if args.LeaderCommit > rf.commitIndex {
4 // If leaderCommit > commitIndex, set commitIndex =
5 // min(leaderCommit, index of last new entry)
6
7 rf.commitIndex = args.LeaderCommit
8
9 if args.LeaderCommit >= len(rf.log)+rf.snapshotLastLogIndex {
10 rf.commitIndex = len(rf.log) - 1 + rf.snapshotLastLogIndex
11 }
12
13 dprintf("[Peer: %d]: Updated commmit index to %d.\n", rf.me, rf.commitIndex)
14
15 rf.applyCond.Signal()
16 }
17}
Why Majority-Based Commitment Guarantees Safety
A critical property of Raft is that once a log entry is committed (replicated on a majority of servers), it is guaranteed to eventually be applied to the state machine even if the current leader crashes immediately after marking it committed.
This guarantee comes from how Raft defines commitment and how election safety works together with log matching.
When a leader replicates a new log entry to a majority of peers and advances its commitIndex, it knows that at least a majority of servers (including itself) now store that entry in their logs. Even if the leader crashes at this point (before or after applying the entry), that entry cannot be lost, because any future leader must have that entry as well.
Here’s why: during the next election, any candidate must receive votes from a majority of peers to become the new leader. And followers will only vote for a candidate whose log is at least as up-to-date as their own, Meaning the candidate’s last log term and index are greater than or equal to the follower’s.
Since the previously committed entry was stored on a majority, at least one of those peers (and in fact, at least one from that same majority) will participate in the next election. Because votes also require a majority, any new leader must intersect with that previous majority i.e., it must share at least one server that already contained the committed entry. As a result, the new leader’s log will contain that committed entry (or a longer version of it), ensuring that committed entries never roll back and will always be part of future leaders’ logs.
This intersection property between consecutive majorities ensures Raft’s log commitment safety:
Once a log entry is committed, it will never be overwritten or lost, It will eventually be applied to the state machine on all servers.
This reasoning also explains why it’s safe for the applier thread to apply all entries up to commitIndex. The guarantee that every future leader’s log contains those entries means that applying them to the state machine can never be undone, preserving Raft’s state machine safety property, no server ever applies a log entry that another server later overwrites.
However, this safety holds under one important restriction, we will discuss this restriction shortly, but first lets see few scenarios with the end client in picture using a service which is replicated with RAFT.
- Leader replication and response to client
At the service layer, this guarantee extends all the way to the client. When a client issues a command to the leader (for example, a PUT request to the key-value server), the service calls the Raft instance’s
Start()method. This appends the command as a new log entry and begins replication across peers (We signal thereplicatorCondcondition variable which resumes thereplicatemethod this time with a new log entry). TheStart()call returns immediately, but the KV service does not reply to the client yet, it waits until that log entry is replicated on a majority of servers and marked as committed. Only after the applier thread applies this entry to the state machine does the service respond to the client with success. This ensures that every command acknowledged to the client is backed by a majority-replicated, committed log entry, one that will survive even if the current leader crashes right after responding. Responding before commitment would be unsafe, since uncommitted entries can be discarded if the leader fails before majority replication completes. To visualize this flow, here’s how the end-to-end interaction between the client, leader, followers, and the KV state machine looks:
sequenceDiagram
participant C as Client
participant L as Leader (KV + Raft)
participant F1 as Follower 1
participant F2 as Follower 2
participant SM as State Machine
C->>L: PUT x=5 (Client Request)
L->>L: Start(cmd) → Append log entry
L->>F1: AppendEntries RPC (new log entry)
L->>F2: AppendEntries RPC (new log entry)
F1-->>L: AppendEntries Reply (Success)
F2-->>L: AppendEntries Reply (Success)
Note over L: Entry replicated on majority
L->>L: Update commitIndex, signal applier
L->>SM: Apply command x=5
SM-->>L: State updated
L-->>C: Success (after apply)
Note over L,C: Client response only after<br/>majority replication & application
- Leader Crashes After Committing but Before Applying:
sequenceDiagram
participant C as Client
participant L as Leader (Term T)
participant F1 as Follower 1
participant F2 as Follower 2
participant L' as New Leader (Term T+1)
C->>L: Start(command)
L->>L: Append log entry [term T, index i]
L->>F1: AppendEntries [entry i]
L->>F2: AppendEntries [entry i]
F1-->>L: Ack
F2-->>L: Ack
L->>L: commitIndex = i (majority replicated)
note right of L: ✅ Command is committed but not yet applied
L--X C: (Crashes before replying)
note over C: ⏱️ Client times out (no response)
C->>L': Retry Start(command)
note right of L': Election happens, new leader<br>contains entry i (since committed)
L'->>L': Apply entry i to state machine
L'-->>C: Respond with result (deduplicated via client ID)
- The leader had committed the log (i.e., replicated to majority), but before applying or responding, it crashed.
- The client times out, since no response was received.
- A new leader is elected (say,
L'), which must contain all committed entries from the previous term. - During recovery,
L'’s applier thread applies the committed command to its state machine. - The client retries the command.
- If the system uses a unique client ID + command ID, the server can detect it’s a duplicate request and not reapply the command, ensuring exactly-once semantics.
Why leader commits log entry when its of currentTerm only?
You may have noticed in the replicate method that when counting majority replication we start form the lastest log index at the leader and if that log’s term is equal to leader’s current term then only we check the replication factor for that log and update commit index and applier thread in case of majority, But why is this the case?
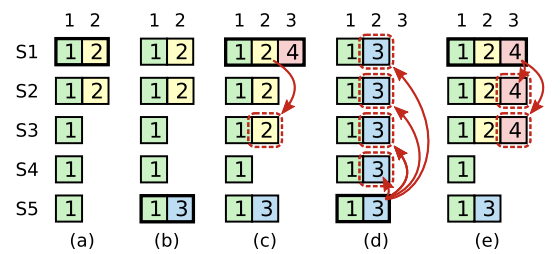 Above image is form the original RAFT paper and it explain the scenario pretty well
Above image is form the original RAFT paper and it explain the scenario pretty well
A time sequence showing why a leader cannot determine commitment using log entries from older terms. In (a) S1 is leader and partially replicates the log entry at index 2. In (b) S1 crashes; S5 is elected leader for term 3 with votes from S3, S4, and itself, and accepts a different entry at log index 2. In (c) S5 crashes; S1 restarts, is elected leader, and continues replication. At this point, the log entry from term 2 has been replicated on a majority of the servers, but it is not committed. If S1 crashes as in (d), S5 could be elected leader (with votes from S2, S3, and S4) and overwrite the entry with its own entry from term 3. However, if S1 replicates an entry from its current term on a majority of the servers before crashing, as in (e), then this entry is committed (S5 cannot win an election). At this point all preceding entries in the log are committed as well.
at point (c) S1 is the leader again and it had log entry from term 2 which it was able to replicate to majority (S1, S2 & S3) but the current term at this point should be atleast 4 since there was already an election for term 3 with leader S5 and at point (c) S1 also appended one log for term 4. Now if at point (d) S1 crashes again S5 can again be elected for term 5 because S2, S3 and S4 will grant vote to S5 because form their point of view S5 has atleast uptodate log with lates log index <= theri own log and term value of 3 whihc is greater than 2. Because of this we cannot allow a log of older terms to be committed because a peer with log of term greater then the term of log replicated to majority can become a leader and as part of log correction erase this older term logs so we cannot commit such logs.
Conclusion
In this second part, we successfully implemented Raft’s Log Replication to build a fault-tolerant in-memory system.
We explored the core mechanics: the leader’s use of the AppendEntries RPC for both sending log entries and serving as a heartbeat, the vital log consistency checks using PrevLogIndex/PrevLogTerm, and the log reconciliation process used by followers to fix conflicts. Finally, we detailed how entries achieve a committed state—only after successful replication to a majority of peers, and are then applied to the state machine by a dedicated applier goroutine.
6.5840 Labs provide us with following test cases for log replication:
1Test (3B): basic agreement (reliable network)...
2 ... Passed -- time 2.1s #peers 3 #RPCs 14 #Ops 0
3Test (3B): RPC byte count (reliable network)...
4 ... Passed -- time 3.3s #peers 3 #RPCs 46 #Ops 0
5Test (3B): test progressive failure of followers (reliable network)...
6 ... Passed -- time 6.4s #peers 3 #RPCs 41 #Ops 0
7Test (3B): test failure of leaders (reliable network)...
8 ... Passed -- time 8.6s #peers 3 #RPCs 68 #Ops 0
9Test (3B): agreement after follower reconnects (reliable network)...
10 ... Passed -- time 5.4s #peers 3 #RPCs 50 #Ops 0
11Test (3B): no agreement if too many followers disconnect (reliable network)...
12 ... Passed -- time 5.2s #peers 5 #RPCs 75 #Ops 0
13Test (3B): concurrent Start()s (reliable network)...
14 ... Passed -- time 2.7s #peers 3 #RPCs 14 #Ops 0
15Test (3B): rejoin of partitioned leader (reliable network)...
16 ... Passed -- time 9.1s #peers 3 #RPCs 81 #Ops 0
17Test (3B): leader backs up quickly over incorrect follower logs (reliable network)...
18 ... Passed -- time 23.8s #peers 5 #RPCs 775 #Ops 0
19Test (3B): RPC counts aren't too high (reliable network)...
20 ... Passed -- time 4.1s #peers 3 #RPCs 30 #Ops 0
In the next part we will see some nuances of log compaction with snapshots and how persistence work currently in lab environment.