This article shares learnings from Google’s influential MapReduce paper and explores the challenges encountered while implementing a simplified version. Our system uses multiple worker processes, running on a single machine and communicating via RPC, to mimic key aspects of a distributed environment.
What is Map-Reduce
At its core, MapReduce is a programming model and an associated framework for processing and generating massive datasets using a parallel, distributed algorithm, typically on a cluster of computers. You might already be familiar with map and reduce operations from functional programming languages. For instance, in JavaScript, array.map() transforms each element of an array independently based on a mapper function, while array.reduce() iterates through an array, applying a reducer function to accumulate its elements into a single output value (e.g., a sum, or a new, aggregated object).
The MapReduce paradigm, brilliantly scales these fundamental concepts to tackle data processing challenges that are orders of magnitude larger than what a single machine can handle. The general flow typically involves several key stages:
Splitting: The vast input dataset is initially divided into smaller, independent chunks. Each chunk will be processed by a Map task.
Map Phase: A user-defined Map function is applied to each input chunk in parallel across many worker machines. The Map function takes an input pair (e.g., a document ID and its content) and produces a set of intermediate key/value pairs. For example, in a word count application, a Map function might take a line of text and output a key/value pair for each word, like (word, 1).
Shuffle and Sort Phase: This is a critical intermediate step. The framework gathers all intermediate key/value pairs produced by the Map tasks, sorts them by key, and groups together all values associated with the same intermediate key. This ensures that all occurrences of (word, 1) for a specific ‘word’ are brought to the same place for the next phase.
Reduce Phase: A user-defined Reduce function then processes the grouped data for each unique key, also in parallel. The Reduce function takes an intermediate key and a list of all values associated with that key. It iterates through these values to produce a final output, often zero or one output value. Continuing the word count example, the Reduce function for a given word would receive (word, [1, 1, 1, …]) and sum these ones to produce the total count, e.g., (word, total_count).
This distributed approach is highly effective for several reasons:
Scalability: It allows for horizontal scaling, you can process more data faster by simply adding more machines to your cluster.
Parallelism: It inherently parallelizes computation, significantly speeding up processing times for large tasks.
Fault Tolerance: The MapReduce framework is designed to handle machine failures automatically by re-executing failed tasks, which is crucial when working with large clusters where failures are common.
This model simplifies large-scale data processing by abstracting away the complexities of distributed programming, such as data distribution, parallelization, and fault tolerance, allowing developers to focus on the logic of their Map and Reduce functions.
The MapReduce Execution Flow
To understand how MapReduce processes vast amounts of data, let’s walk through the typical execution flow, as illustrated in the Google paper and its accompanying diagram (Figure 1 from the paper, shown below). This flow is orchestrated by a central Master (or Coordinator, as in our lab implementation) and executed by multiple Worker processes.
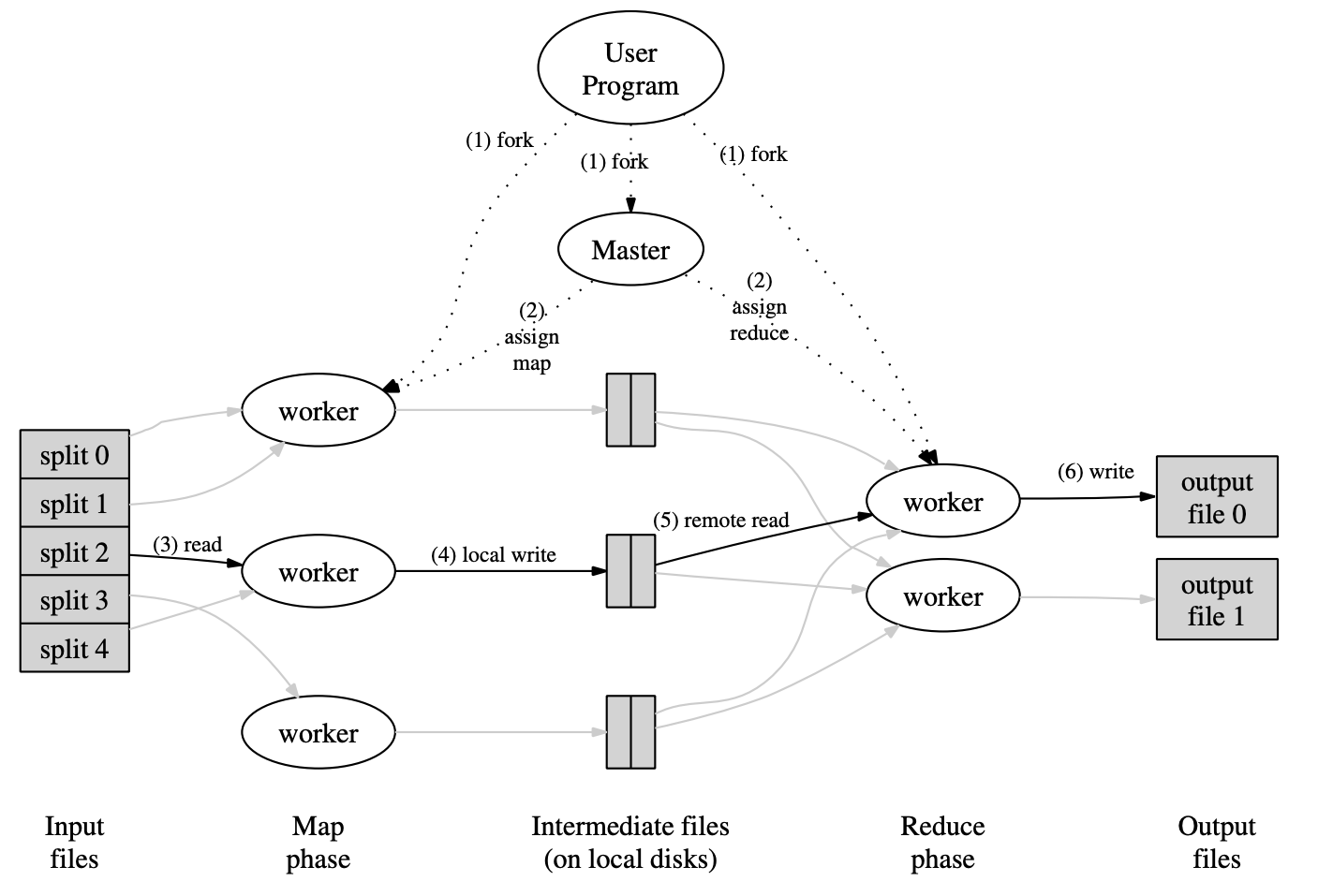
Here’s a breakdown of the key stages:
Initialization & Input Splitting (Diagram: User Program forks Master, Input files split):
- The MapReduce library first divides the input files into
Msmaller, manageable pieces called splits (e.g., split 0 to split 4 in the diagram). Each split is typically16-64MB. - The User Program then starts multiple copies of the program on a cluster. One copy becomes the Master, and the others become Workers. Here the binary contains logic for master and worker as part of map-reduce library.
- The MapReduce library first divides the input files into
Task Assignment by Master (Diagram: Master assigns map/reduce to workers):
- The Master is the central coordinator. It’s responsible for assigning tasks to idle workers. There are
Mmap tasks (one for each input split) andRreduce tasks (a number chosen by the user for the desired level of output parallelism).
- The Master is the central coordinator. It’s responsible for assigning tasks to idle workers. There are
Map Phase - Processing Input Splits (Diagram: worker (3) reads split, (4) local write):
- A worker assigned a map task reads the content of its designated input split (e.g., split 2).
- It parses key/value pairs from this input data. For each pair, it executes the user-defined Map function. The Map function emits intermediate key/value pairs.
- These intermediate pairs are initially buffered in the worker’s memory. Periodically, they are written to the worker’s local disk. Crucially, these locally written intermediate files are partitioned into R regions/files (one region/file for each eventual reduce task). This is typically done using a partitioning function (e.g., hash(intermediate_key) % R).
- The locations of these R partitioned files on the local disk (shown as “Intermediate files (on local disks)” in the diagram) are then reported back to the Master. The Master now knows where the intermediate data for each reduce task partition resides, spread across possibly many map workers.
Reduce Phase - Aggregating Intermediate Data (Diagram: worker (5) remote read, (6) write output):
- Once the Master sees that map tasks are completing, it begins assigning reduce tasks to other (or the same) workers.
- When a reduce worker is assigned a partition (say, partition j out of R), the Master provides it with the locations of all the relevant intermediate files (i.e., the j-th region/file from all map workers that produced j-th intermediate file).
- The reduce worker then performs remote reads from the local disks of the map workers to fetch this buffered intermediate data.
- After retrieving all necessary intermediate data for its assigned partition, the reduce worker sorts these key/value pairs by the intermediate key. This groups all occurrences of the same key together. (If data is too large for memory, an external sort is used).
- The worker then iterates through the sorted data. For each unique intermediate key, it calls the user-defined Reduce function, passing the key and the list of all associated intermediate values.
- The output of the Reduce function is appended to a final output file for that specific reduce partition (e.g., output file 0, output file 1). There will be R such output files.
Job Completion:
- When all
Mmap tasks andRreduce tasks have successfully completed, the Master signals the original User Program. - The
MapReducecall in the user code returns, and the results are available in theRoutput files.
- When all
Key Design Decisions:
- Abstraction: Developers focus on
MapandReducelogic, while the framework manages distributed complexities like data partitioning, parallel execution, and shuffling. - Inherent Fault Tolerance: The system is designed for resilience against common failures:
- The Master detects worker failures. If a worker assigned a map task fails, the task is re-assigned because its input split is durable.
- More subtly, if a worker completes a map task (producing intermediate files on its local disk) but then fails before all necessary reduce tasks have read those intermediate files, those files are lost. The Master must then reschedule that original map task on another worker to regenerate its intermediate output.
- If a worker assigned a reduce task fails, that reduce task can be re-executed by another worker.
- However, once a reduce task completes successfully and writes its final output (e.g., to mr-out-X), that output is considered final. The system aims to avoid re-executing successfully completed reduce tasks, relying on the durability of their output.
One important aspect to note is that intermediate files are stored on the local file system of the worker nodes that produce them. This design choice is deliberate: by keeping intermediate data local, the system significantly reduces network bandwidth consumption and potential network congestion that would arise if all intermediate data had to be written to, and read from, a global file system. However, this means that crashes in map worker nodes can result in the loss of their locally stored intermediate data, requiring the re-execution of those map tasks.
In contrast, the final outputs of worker processes executing the reduce operation are typically written to a global, distributed file system (like GFS in Google’s case). Once a reduce task successfully writes its output to this global system, it’s considered durable and generally does not need to be re-executed, even if the worker that produced it later fails.
Implementing MapReduce in Go: The Coordinator and Worker
The Go implementation translates the conceptual MapReduce master-worker architecture into two main programs: a Coordinator and multiple Worker processes, communicating via RPC. We’ll explore the key parts of their implementation, starting with the Coordinator.
The Coordinator (mr/coordinator.go)
The Coordinator is the central manager of the MapReduce job. Its primary role is to distribute tasks to workers, track their progress, handle failures, and determine when the overall job is complete.
- Initialization (
MakeCoordinator) TheMakeCoordinatorfunction initializes the Coordinator’s state. It’s called bymain/mrcoordinator.gowith the input files and the number of reduce tasks (nReduce).
1// MakeCoordinator is called by main/mrcoordinator.go to create and initialize
2// the coordinator for a MapReduce job.
3// - files: A slice of input file paths for the map tasks.
4// - nReduce: The desired number of reduce tasks.
5func MakeCoordinator(files []string, nReduce int) *Coordinator {
6 // Step 1: Initialize the list of ready Map tasks.
7 // NewTaskList() creates a new instance of TaskList (wrapper around container/list).
8 readyTaskList := NewTaskList()
9
10 // For each input file, a Map task is created.
11 for index, file := range files {
12 readyTaskList.AddTask(&Task{ // Task struct holds details for a single map or reduce operation.
13 Filename: file, // Input file for this map task.
14 Status: StatusReady, // Initial status: ready to be assigned.
15 Type: MapType, // Task type is Map.
16 Id: TaskId(fmt.Sprintf("m-%d", index)), // Unique ID for the map task (e.g., "m-0").
17 })
18 }
19
20 // Step 2: Initialize the Coordinator struct with its core state variables.
21 c := Coordinator{
22 // --- Task Tracking ---
23 // readyTasks: Holds tasks (initially all Map tasks, later Reduce tasks) that are
24 // waiting to be assigned to a worker.
25 // Managed by GetTask (removes) and ReportTask/checkWorkerStatus (adds back on failure).
26 readyTasks: *readyTaskList,
27
28 // runningTasks: A map from TaskId to *RunningTask. Tracks tasks currently assigned
29 // to one or more workers. A RunningTask includes the Task details and a
30 // list of WorkerIds processing it.
31 // Managed by GetTask (adds) and ReportTask/checkWorkerStatus (modifies/removes).
32 runningTasks: make(map[TaskId]*RunningTask),
33
34 // successTasks: A map from TaskId to *Task. Stores tasks that have been successfully
35 // completed by a worker.
36 // Managed by ReportTask (adds on success).
37 successTasks: make(map[TaskId]*Task),
38
39 // --- Job Parameters & Phase Control ---
40 // nReduce: The target number of reduce partitions/tasks for the job.
41 // Used by Map workers to partition intermediate data and by the Coordinator
42 // to determine when all reduce tasks are done.
43 nReduce: nReduce,
44
45 // nMap: The total number of map tasks, simply the count of input files.
46 // Used to determine when all map tasks are done.
47 nMap: len(files),
48
49 // pendingMappers: A counter for map tasks that are not yet successfully completed.
50 // Crucially used in GetTask to gate the start of Reduce tasks –
51 // Reduce tasks cannot begin until pendingMappers is 0.
52 // Decremented in ReportTask upon successful map task completion.
53 pendingMappers: len(files),
54
55 // --- Intermediate Data Management ---
56 // intermediateFiles: An IntermediateFileMap (map[string]map[WorkerId][]string).
57 // This is vital: maps a partition key (string, for a reduce task)
58 // to another map. This inner map links a WorkerId (of a map worker)
59 // to a list of filenames (intermediate files produced by that map worker
60 // for that specific partition key).
61 // Populated in ReportTask when a Map task succeeds.
62 // Read by GetTask to provide Reduce workers with their input locations.
63 intermediateFiles: make(IntermediateFileMap),
64
65 // --- Worker Tracking ---
66 // workers: A map from WorkerId to *WorkerMetdata. Stores metadata about each worker
67 // that has interacted with the coordinator. WorkerMetdata includes:
68 // - lastHeartBeat: Time of the worker's last contact, used by checkWorkerStatus for timeouts.
69 // - runningTask: TaskId of the task currently assigned to this worker.
70 // - successfulTasks: A map of tasks this worker has completed (useful for debugging/optimizations, not strictly essential for basic fault tolerance in this lab's context if tasks are just re-run).
71 // Populated/updated in GetTask and ReportTask.
72 workers: make(map[WorkerId]*WorkerMetdata),
73
74 // --- Coordinator Shutdown & Job Completion Signaling ---
75 // finished: A boolean flag set to true when all map and reduce tasks are successfully
76 // completed (checked in ReportTask). Signals the main job is done.
77 finished: false,
78
79 // done: A channel of empty structs (chan struct{}). Used to signal background goroutines
80 // (like checkWorkerStatus) to terminate gracefully when the job is `finished`.
81 // Closed in the Done() method.
82 done: make(chan struct{}),
83
84 // shutdownSignaled: A boolean flag, true after `done` channel is closed. Prevents
85 // multiple closures or redundant shutdown logic.
86 shutdownSignaled: false,
87
88 // allGoroutinesDone: A boolean flag, true after `wg.Wait()` in `Done()` confirms all
89 // background goroutines have exited.
90 allGoroutinesDone: false,
91 // wg (sync.WaitGroup): Used in conjunction with `done` to wait for background goroutines
92 // to complete their cleanup before the Coordinator fully exits.
93 // Incremented before launching a goroutine, Done called in goroutine's defer.
94 // (wg is part of the Coordinator struct, initialized implicitly here)
95 }
96
97 fmt.Printf("Initialised ready tasklist of %d tasks\n", len(files))
98
99 // Step 3: Start Services
100 // Start the RPC server so the coordinator can listen for requests from workers.
101 // This makes methods like GetTask and ReportTask callable by workers.
102 c.server()
103
104 // Step 4: Launch Background Health Checker Goroutine
105 // This goroutine is responsible for fault tolerance, specifically detecting
106 // and handling timed-out (presumed crashed) workers.
107 c.wg.Add(1) // Increment WaitGroup counter before launching the goroutine.
108 go func() {
109 defer c.wg.Done() // Decrement counter when the goroutine exits.
110 for {
111 select {
112 case <-c.done: // Listen for the shutdown signal from the main coordinator logic.
113 fmt.Printf("[Coordinator Shutdown]: Closing worker health check background thread.\n")
114 return // Exit the goroutine.
115 default:
116 // Periodically call checkWorkerStatus to handle unresponsive workers.
117 c.checkWorkerStatus()
118 // WORKER_TIMEOUT_SECONDS is 10s, so this checks every 5s.
119 time.Sleep(WORKER_TIMEOUT_SECONDS / 2)
120 }
121 }
122 }()
123
124 return &c // Return the initialized Coordinator instance.
125}
- Initially,
Mmap tasks are created (one for each input file) and added toreadyTasks. - Contrary to the paper we can only run reduce tasks only when all mapper tasks are finished as input for a reduce task may require intermediate file output(s) from more than one map task since a map task produces at max
Rintermediate partition files, each designated to one reduce task and reduce workers needs to fetch these intermediate files from each of the mapper worker’s local file system. - An RPC server (
c.server()) is started for worker communication, and a backgroundgoroutine (checkWorkerStatus)is launched for fault tolerance. All shared state within the Coordinator (e.g., task lists, worker metadata) must be protected by mutexes (as seen in its methods likeGetTask,ReportTask) since the shared state can be accessed by multiple go routines handling RPC calls from various workers processes which may lead to race conditions.
- Assigning Tasks to Workers (
GetTaskRPC Handler) Workers call theGetTaskRPC handler to request jobs (either Map or Reduce tasks) from the Coordinator.
1// An RPC handler to find next available task (map or reduce)
2func (c *Coordinator) GetTask(args *GetTaskArgs, reply *GetTaskReply) error {
3 c.mu.Lock()
4 defer c.mu.Unlock()
5
6 workerMetadata, ok := c.workers[args.WorkerId]
7
8 // Requesting worker already processing a task
9 // Skip task assignment
10 if ok && workerMetadata.runningTask != "" {
11 fmt.Printf("[GetTask]: Worker %d already processing task %s, rejecting task assignment request.\n", args.WorkerId, workerMetadata.runningTask)
12 return nil
13 }
14
15 if c.readyTasks.GetTaskCount() == 0 {
16 // No tasks available
17 // map reduce is complete if we also have len(runningTasks) == 0
18 // Sending InvalidType task in such cases to worker
19 reply.Task = Task{
20 Type: InvalidType,
21 }
22 return nil
23 }
24
25 task := c.readyTasks.RemoveTask()
26
27 // Skipping tasks that are possible retrials with an instance already completed and part of success set
28 // It is possible that a task here already has a status of `StatusRunning` we are not skipping such tasks in ready queue
29 // This will result in multiple instances of same task execution, This case is possible if previous worker processing the task
30 // failed/crashed (timeout of not reporting reached) and we added another instance of the same task.
31 // Even if two workers report completion of same task only one of them will remove the task from running queue and add it to
32 // success set, Reporting by slower worker will be skipped.
33
34 // Only assing a reduce task when we are sure there is no pending map task left
35 // Since then reduce task will surely fail because of unavailabiltiy of intermeidate fiel data
36 for task != nil {
37 if task.Status == StatusSuccess || (task.Type == ReduceType && c.pendingMappers > 0) {
38 if task.Status == StatusSuccess {
39 fmt.Printf("[GetTask]: Skipping ready task %s since it is already successfully completed\n", task.Id)
40 } else {
41 fmt.Printf("[GetTask]: Skipping reduce task %s since there are %d pending mappers\n", task.Id, c.pendingMappers)
42 }
43 task = c.readyTasks.RemoveTask()
44 } else {
45 break
46 }
47 }
48
49 // Either all tasks are completed (if len(runningTasks) == 0)
50 // OR all tasks are currently being processed by some workers
51 if task == nil {
52 reply.Task = Task{
53 Type: InvalidType,
54 }
55 fmt.Printf("[GetTask]: No task to assign to worker %d, # Tasks Running : %d, # Tasks Completed: %d\n", args.WorkerId, len(c.runningTasks), len(c.successTasks))
56 return nil
57 }
58
59 fmt.Printf("[GetTask]: Found a task with id %s for worker %d. Current Task Status: %v\n", task.Id, args.WorkerId, task.Status)
60
61 // Found a task with Status as either `StatusError` or `StatusReady` or `StatusRunning`
62 // If task's status is: `StatusError`` -> Retrying failed task again
63 // If task's status is `StatusReady` -> First Attempt of processing of task
64 // If task's status is `StatusRunning` -> Retrying already running task due to delay from previous assigned worker
65 task.Worker = args.WorkerId
66 task.StartTime = time.Now()
67 task.Status = StatusRunning
68 reply.Task = *task
69
70 if task.Type == ReduceType {
71 // Add intermediate file locations collected from various map executions
72 reply.IntermediateFiles = c.intermediateFiles[task.Filename]
73 }
74
75 reply.NR = c.nReduce
76
77 // Update list of workers currently processing a taskId
78 rt := c.runningTasks[task.Id]
79
80 if rt == nil {
81 c.runningTasks[task.Id] = &RunningTask{}
82 }
83 c.runningTasks[task.Id].task = task
84
85 c.runningTasks[task.Id].workers = append(c.runningTasks[task.Id].workers, args.WorkerId)
86
87 if workerMetadata != nil {
88 workerMetadata.lastHeartBeat = time.Now()
89 workerMetadata.runningTask = task.Id
90 } else {
91 c.workers[args.WorkerId] = &WorkerMetdata{
92 lastHeartBeat: time.Now(),
93 runningTask: task.Id,
94 successfulTasks: make(map[TaskId]*TaskOutput),
95 }
96 }
97
98 return nil
99}
- As defined in the paper’s step-2 of the execution flow this method is called by various workers to request task which are in
readyTasks. - It deals with scenarios like workers already being busy, no tasks being available, or tasks being unsuitable for immediate assignment (e.g., reduce tasks when mappers are still active).
- If a valid task is found all necessary details to execute that task are populated in
GetTaskReplystruct. For Map tasks, it implicitly provides the input file (viatask.Filename). For Reduce tasks, it explicitly provides the locations of all relevant intermediate files and the total number of reducers (nR).
- Handling Task Completion/Failure (
ReportTaskRPC Handler) Workers callReportTaskto inform the coordinator about the outcome of their assigned task.
1func (c *Coordinator) ReportTask(args *ReportTaskArgs, reply *ReportTaskReply) error {
2 c.mu.Lock()
3 defer c.mu.Unlock()
4
5 reply.Status = true // optimistic reply
6
7 taskSuccessInstance := c.successTasks[args.Task.Id]
8 // ... (validation: check if task already completed, if worker owns task) ...
9
10 // Reported task is already in success set.
11 // Possibly retried after timeout by another worker
12 // One of the worker complted the task.
13 if taskSuccessInstance != nil {
14 fmt.Printf("[ReportTask]: Task %s has already been completed by worker %d\n", taskSuccessInstance.Id, taskSuccessInstance.Worker)
15 // ... (update worker metadata) ...
16 return nil
17 }
18
19 // ... (check if worker lost ownership of the task) ...
20
21
22 if args.Task.Status == StatusError {
23 fmt.Printf("[ReportTask]: Task %s reported with status %v by worker %d\n", args.Task.Id, args.Task.Status, args.Task.Worker)
24 // ... (disown worker from task) ...
25 // If no other worker is processing this task, add it back to readyTasks
26 if len(c.runningTasks[args.Task.Id].workers) == 0 {
27 task := args.Task
28 task.Worker = 0
29 task.StartTime = time.Time{}
30 task.Status = StatusReady
31 c.readyTasks.AddTask(&task)
32 }
33 return nil
34 }
35
36 if args.Task.Status == StatusSuccess {
37 switch args.Task.Type {
38 case MapType:
39 intermediateFiles := args.Task.Output
40 fmt.Printf("[ReportTask]: Mapper Task %s completed successfully by worker %d, produced following intermediate files: %v\n", args.Task.Id, args.Task.Worker, intermediateFiles)
41
42 for _, filename := range intermediateFiles {
43 partitionKey := strings.Split(filename, "-")[4] // Assumes filename format like w-<workerId>/mr-m-<taskId>-<hash>
44 paritionFiles, ok := c.intermediateFiles[partitionKey]
45 if !ok || paritionFiles == nil {
46 paritionFiles = make(map[WorkerId][]string)
47 }
48 paritionFiles[args.Task.Worker] = append(paritionFiles[args.Task.Worker], filename)
49 c.intermediateFiles[partitionKey] = paritionFiles
50 }
51 // ... (update worker metadata, move task to successTasks, decrement pendingMappers) ...
52 delete(c.runningTasks, args.Task.Id)
53 c.successTasks[args.Task.Id] = &args.Task
54 c.pendingMappers--
55
56 if c.pendingMappers == 0 {
57 fmt.Printf("\nAll map task ran successfully. Tasks Run Details: \n %v \n", c.successTasks)
58 c.addReduceTasks() // Trigger creation of reduce tasks
59 }
60 case ReduceType:
61 // ... (update worker metadata, move task to successTasks) ...
62 delete(c.runningTasks, args.Task.Id)
63 c.successTasks[args.Task.Id] = &args.Task
64
65 if len(c.successTasks) == c.nMap+c.nReduce {
66 fmt.Printf("\nAll reduce tasks ran successfully. Tasks Run Details: \n %v \n", c.successTasks)
67 c.finished = true // Mark entire job as done
68 }
69 default:
70 // ...
71 }
72 // ... (logging) ...
73 }
74 return nil
75}
76
77// ... (helper function addReduceTasks)
78func (c *Coordinator) addReduceTasks() {
79 index := 0
80 for partition, v := range c.intermediateFiles { // Iterate over collected partitions
81 task := Task{
82 Status: StatusReady,
83 Type: ReduceType,
84 Id: TaskId(fmt.Sprintf("r-%d", index)),
85 Filename: partition, // Partition key becomes the 'filename' for the reduce task
86 }
87 if c.successTasks[task.Id] == nil { // Avoid re-adding if already processed (e.g. due to retries)
88 c.readyTasks.AddTask(&task)
89 fmt.Printf("Reduce Task with Id %s Added to ready queue (Intermediate partition %s with %d files)\n", task.Id, partition, len(v))
90 }
91 index++
92 }
93 c.nReduce = index // Update nReduce to actual number of partitions, good for robustness
94}
- If a task is reported with
StatusError, and it’s the only instance of that task running, it’s re-queued for a later attempt. This is a core part of fault tolerance. - Processes Successful Map Tasks:
- Collects and organizes the locations of intermediate files (output of Map functions) based on their partition key. This information (
c.intermediateFiles) is vital for the subsequent Reduce phase, as it tells Reduce workers where to fetch their input data. This aligns with step 4 of the paper’s flow. - Decrements
pendingMappers. When all mappers are done, it triggersaddReduceTasks. - Once all Map tasks are complete,
addReduceTasksis called. It iterates through all the unique partition keys derived from the intermediate files and creates oneReducetask for each, adding them to thereadyTasksqueue.
- Collects and organizes the locations of intermediate files (output of Map functions) based on their partition key. This information (
- Processes Successful Reduce Tasks:
- Marks the reduce task as complete.
- Checks if all Map and Reduce tasks for the entire job are finished. If so, it sets
c.finished = true, signaling that the Coordinator can begin shutting down.
- By checking
c.successTasksat the beginning, it avoids reprocessing reports for tasks already marked as successful, which helps in scenarios with duplicate or late messages.
- Fault Tolerance (
checkWorkerStatus) A backgroundgoroutineperiodically checks for unresponsive workers.
1func (c *Coordinator) checkWorkerStatus() {
2 c.mu.Lock()
3 defer c.mu.Unlock()
4
5 for workerId, metadata := range c.workers {
6 lastHeartBeatDuration := time.Since(metadata.lastHeartBeat)
7
8 if metadata.runningTask != "" && lastHeartBeatDuration >= WORKER_TIMEOUT_SECONDS {
9 fmt.Printf("Worker %d have not reported in last %s\n", workerId, lastHeartBeatDuration)
10 taskToRetry := make([]*Task, 0)
11
12 runningTask := c.runningTasks[metadata.runningTask]
13 if runningTask == nil {
14 // This case should ideally not happen if state is consistent
15 fmt.Printf("[checkWorkerStatus]: Local worker state shows worker %d running rask %s whereas global running tasks state does not show any worker for the same task.\n", workerId, metadata.runningTask)
16 // Potentially clear worker's running task if inconsistent: metadata.runningTask = ""
17 continue // or return, depending on desired error handling
18 }
19
20 taskToRetry = append(taskToRetry, runningTask.task)
21 metadata.runningTask = "" // Worker is no longer considered running this task
22
23 // Remove this worker from the list of workers for the task
24 runningTask.workers = slices.DeleteFunc(runningTask.workers, func(w WorkerId) bool {
25 return w == workerId
26 })
27
28 // If this was the only worker on this task, or if we want to aggressively reschedule
29 // (The current code implies rescheduling if *any* assigned worker times out, which is fine for this lab)
30 if len(taskToRetry) > 0 { // Will always be true if runningTask was not nil
31 for _, task := range taskToRetry {
32 fmt.Printf("[checkWorkerStatus]: Adding task %s of type %d with status %d back to the ready queue.\n", task.Id, task.Type, task.Status)
33
34 // Reset task for retry
35 task.Status = StatusReady
36 task.Worker = 0 // Clear previous worker assignment
37 task.Output = make([]string, 0) // Clear previous output
38
39 c.readyTasks.AddTask(task)
40 }
41 }
42 }
43 // ... (logging for active workers) ...
44 }
45}
Key Decisions Upon Detecting a Failed Worker:
- Identify the Affected Task: The primary task to consider is
metadata.runningTask, which the failed worker was supposed to be executing. The details of this task are retrieved fromc.runningTasks. - Update Worker’s State: The failed worker’s
metadata.runningTaskis cleared, indicating it’s no longer considered to be working on that task by the coordinator. - Update Task’s Worker List: The failed
workerIdis removed from therunningTaskEntry.workerslist, which tracks all workers assigned to that specific task ID. - Reset Task for Re-execution: The affected taskInstanceToRetry undergoes several state changes:
- Status is set back to
StatusReady, making it available in thec.readyTasksqueue. Worker(assigned worker ID) is cleared.StartTimeis reset.Output(list of output files) is cleared, as any partial output is now suspect or irrelevant.
- Status is set back to
- Re-queue the Task: The reset task is added back to
c.readyTasks.AddTask(task). This ensures another worker can pick it up.
Handling Lost Intermediate Data (Implicitly via Task Re-execution):
A critical aspect of fault tolerance in MapReduce, as highlighted by the paper, is managing the intermediate files produced by map tasks. These are typically stored on the local disks of the map workers. If a map worker completes its task successfully but then crashes before all relevant reduce tasks have consumed its intermediate output, those intermediate files are lost.
Our current checkWorkerStatus implementation primarily focuses on retrying the actively running task of a worker that times out.
1// In checkWorkerStatus, when a worker (workerId) times out:
2// ...
3runningTask := c.runningTasks[metadata.runningTask]
4// ...
5taskToRetry = append(taskToRetry, runningTask.task) // The currently running task is added for retry
6metadata.runningTask = ""
7// ... task is reset and added back to c.readyTasks ...
This handles cases where a worker fails mid-task. But what about its previously completed map tasks whose outputs are now gone?
The Challenge of Retrying Previously Successful Map Tasks
One might initially think that upon a worker’s crash, we should re-queue all map tasks that worker had successfully completed. The following (commented-out) snippet from an earlier version of checkWorkerStatus attempted this:
1// Original (commented-out) consideration for retrying all successful map tasks of a crashed worker:
2
3// Adding successful map tasks of this worker for retrial
4for taskId, _ := range metadata.successfulTasks {
5 if c.successTasks[taskId] != nil && c.successTasks[taskId].Type == MapType {
6 // If this task was indeed in the global success set and was a MapType:
7 taskToRetry = append(taskToRetry, c.successTasks[taskId]) // Add it for retrial
8 delete(c.successTasks, taskId) // Remove from global success set
9 // CRITICAL: We would also need to increment c.pendingMappers here if it had been decremented
10 c.pendingMappers++
11 }
12}
13
14// Tombstoning metadata of intermediate files produced by this worker
15// From global state so that downstream reduce workers get to know about the failure.
16// This would ideally cause reduce tasks that depend on this worker's output to fail
17// or wait, and get re-added after the map tasks are re-run.
18for _, v := range c.intermediateFiles {
19 // Mark intermediate files from this worker (workerId) as unavailable/invalid.
20 delete(v, workerId) // Or v[workerId] = nil if the structure supports it
21}
When a map worker crashes after successfully writing its intermediate files, those files (on its local disk) are lost in a true distributed system. Our lab setup, where all workers share the host’s filesystem, can sometimes mask this; a ‘crashed’ worker’s files might still be accessible. This is a crucial difference from a production environment. Simply re-queuing all successfully completed map tasks from a crashed worker can be inefficient:
- Performance Hit: It can lead to significant re-computation and potential test timeouts, especially if many map tasks were already done by a worker which crashed.
- Complexity: Managing
pendingMappersand preventing reduce tasks from starting prematurely adds complexity if many map tasks are suddenly re-added.
A More Targeted Optimization (Future Scope): A more refined approach is to only re-run a successful map task from a crashed worker if its specific output intermediate partitions are actually needed by currently pending (not yet completed) reduce tasks.
This involves:
Identifying which map tasks the crashed worker completed.
Determining if their output partitions are required by any active or future reduce tasks.
Only then, re-queueing those specific map tasks and invalidating their previous intermediate file locations.
Not to prevent all reduce task from processing and maintain list of reduce task which should be skipped if scheduled based on lost intermediate files state from a crashed worker.
This smarter retry avoids redundant work but increases coordinator complexity. For our lab, focusing on retrying the currently running task of a failed worker proved sufficient to pass the tests, partly due to the shared filesystem behaviour making the storage of intermediate files also in some sense to global filesystem
In essence, checkWorkerStatus implements the “timeout and retry” strategy. It ensures that work assigned to unresponsive workers is not indefinitely stalled and is eventually re-assigned, which is fundamental for making progress in a distributed system prone to failures.
- Job Completion (Done)
main/mrcoordinator.goperiodically callsDone()to check if the entire job is finished.
1// main/mrcoordinator.go calls Done() periodically to find out
2// if the entire job has finished.
3func (c *Coordinator) Done() bool {
4 c.mu.Lock()
5
6 // If the job is marked as finished and we haven't started the shutdown sequence for goroutines yet
7 if c.finished && !c.shutdownSignaled {
8 fmt.Printf("[Coordinator Shutdown]: MR workflow completed. Signaling internal goroutines to stop.\n")
9 close(c.done) // Signal all listening goroutines
10 c.shutdownSignaled = true // Mark that we've signaled them
11 }
12
13 // If we have signaled for shutdown, but haven't yet confirmed all goroutines are done
14 if c.shutdownSignaled && !c.allGoroutinesDone {
15 c.mu.Unlock()
16 c.wg.Wait() // Wait for all goroutines (like the health checker) to call c.wg.Done()
17 c.mu.Lock()
18 c.allGoroutinesDone = true
19 fmt.Printf("[Coordinator Shutdown]: All internal goroutines have completed.\n")
20 }
21
22 isCompletelyDone := c.finished && c.allGoroutinesDone
23 c.mu.Unlock()
24 return isCompletelyDone
25}
The Worker (mr/worker.go)
The Worker process is responsible for executing the actual Map and Reduce functions as directed by the Coordinator. Each worker operates independently, requesting tasks, performing them, and reporting back the results.
- Worker’s Main Loop (
Workerfunction) The Worker function, called bymain/mrworker.go, contains the main operational loop.
1var workerId WorkerId = WorkerId(os.Getpid()) // Unique ID for this worker process
2var dirName string = fmt.Sprintf("w-%d", workerId) // Worker-specific directory for temp files
3
4// ... (Log, ihash functions) ...
5
6// main/mrworker.go calls this function.
7func Worker(mapf func(string, string) []KeyValue,
8 reducef func(string, []string) string) {
9 Log("Started")
10
11 // Create a worker-specific directory if it doesn't exist.
12 // Used for storing temporary files before atomic rename.
13 if _, err := os.Stat(dirName); os.IsNotExist(err) {
14 err := os.Mkdir(dirName, 0755)
15 // ... (error handling) ...
16 }
17
18 getTaskargs := GetTaskArgs{ // Prepare args for GetTask RPC
19 WorkerId: workerId,
20 }
21
22 for { // Main loop: continuously ask for tasks
23 getTaskReply := GetTaskReply{}
24 Log("Fetching task from coordinator...")
25 ok := call("Coordinator.GetTask", &getTaskargs, &getTaskReply)
26
27 if ok { // Successfully contacted Coordinator
28 task := &getTaskReply.Task
29 nReduce := getTaskReply.NR // Number of reduce partitions
30
31 switch task.Type {
32 case MapType:
33 Log(fmt.Sprintf("Assigned map job with task id: %s", task.Id))
34 processMapTask(task, nReduce, mapf) // Execute the map task
35 case ReduceType:
36 Log(fmt.Sprintf("Assigned reduce job with task id: %s", task.Id))
37 intermediateFiles := getTaskReply.IntermediateFiles // Get locations from Coordinator
38 processReduceTask(task, intermediateFiles, reducef) // Execute reduce task
39 default: // InvalidType or unknown
40 Log("Invalid task recieved or no tasks available. Sleeping.")
41 }
42
43 // If a valid task was processed (not InvalidType), report its status
44 if task.Type != InvalidType {
45 reportTaskArgs := ReportTaskArgs{ Task: *task }
46 reportTaskReply := ReportTaskReply{}
47 ok = call("Coordinator.ReportTask", &reportTaskArgs, &reportTaskReply)
48 if !ok || !reportTaskReply.Status {
49 Log("Failed to report task or coordinator indicated an issue. Exiting.")
50 // The lab hints that if a worker can't contact the coordinator,
51 // it can assume the job is done and the coordinator has exited.
52 removeLocalWorkerDirectory() // Clean up worker-specific directory
53 return
54 }
55 }
56 // Brief pause before asking for the next task.
57 time.Sleep(WORKER_SLEEP_DURATION) // WORKER_SLEEP_DURATION is 2s
58 } else { // Failed to contact Coordinator
59 Log("Failed to call 'Coordinator.GetTask'! Coordinator not found or exited. Exiting worker.")
60 // removeLocalWorkerDirectory() // Cleanup if needed, though not strictly required by lab on exit
61 return // Exit the worker process
62 }
63 }
64}
- Core Logic: Continuously polls the Coordinator for tasks (
Coordinator.GetTask). Based on the task type (MapTypeorReduceType), it calls the respective processing function. After processing, it reports the outcome to the Coordinator (Coordinator.ReportTask). - Exit Condition: If communication with the Coordinator fails (e.g.,
GetTaskRPC fails), the worker assumes the job is complete and the Coordinator has shut down, so the worker also exits. This is a simple shutdown mechanism compliant with the lab requirements. - Local Directory: Each worker maintains a local directory (
dirName like w-workerId) for its temporary files, ensuring isolation before final output naming.
- Processing Map Tasks (
processMapTask)
1// Processes map task by fetching `Filename` from Task
2// Calls provided mapf function and stores intermediate files after
3// paritioninng them based on `ihash` function
4func processMapTask(task *Task, nReduce int, mapf func(string, string) []KeyValue) error {
5 Log(fmt.Sprintf("Processing map task with id %s and file: %s", task.Id, task.Filename))
6
7 file, err := os.Open(task.Filename) // Open the input split (file)
8 // ... (error handling: set task.Status = StatusError, return) ...
9 content, err := io.ReadAll(file) // Read the entire file content
10 // ... (error handling: set task.Status = StatusError, return) ...
11 file.Close()
12
13 intermediate := mapf(task.Filename, string(content)) // Execute the user-defined map function
14
15 // Group intermediate key-value pairs by partition
16 buckets := make(map[int][]KeyValue)
17 for _, kv := range intermediate {
18 partition := ihash(kv.Key) % nReduce // Determine partition using ihash
19 buckets[partition] = append(buckets[partition], kv)
20 }
21
22 task.Output = []string{} // Clear previous output, prepare for new output filenames
23
24 // For each partition, sort and write to a temporary intermediate file
25 for partition, kva := range buckets {
26 // In-memory sort for this partition's KeyValue pairs.
27 // The paper mentions external sort if data is too large, but here it's in-memory.
28 sort.Sort(ByKey(kva))
29
30 // Create a temporary file in the worker's specific directory.
31 tempFile, err := os.CreateTemp(dirName, "mwt-*") // "mwt" for map worker temp
32 // ... (error handling: set task.Status = StatusError, return) ...
33
34 enc := json.NewEncoder(tempFile)
35 for _, kv := range kva { // Write sorted KeyValue pairs to the temp file using JSON encoding
36 err := enc.Encode(&kv)
37 // ... (error handling: set task.Status = StatusError, tempFile.Close(), return) ...
38 }
39 tempFile.Close() // Close after writing
40
41 // Atomically rename the temporary file to its final intermediate name.
42 // Filename format: mr-<map_task_id>-<partition_number> (e.g., mr-m-0-1)
43 // Stored within the worker's directory: w-<workerId>/mr-m-0-1
44 intermediateFilename := filepath.Join(dirName, fmt.Sprintf("mr-%s-%d", task.Id, partition))
45 err = os.Rename(tempFile.Name(), intermediateFilename)
46 // ... (error handling: set task.Status = StatusError, return) ...
47
48 task.Output = append(task.Output, intermediateFilename) // Add final filename to task's output list
49 }
50
51 task.Status = StatusSuccess // Mark task as successful
52 return nil
53}
- Core Logic: Reads the assigned input file, applies the user-defined
mapf, partitions the output KeyValue pairs usingihash() % nReduce, sorts each partition’s data in memory, and writes it to a uniquely named intermediate file within its local directory. - Intermediate Files: Output filenames (e.g.,
w-workerId/mr-mapTaskID-partitionID) are collected intask.Output. - Atomic Rename: Uses
os.Renameto make intermediate files visible only once fully written, preventing partial reads by reducers. This is crucial for consistency, especially if crashes occur. - In-Memory Sort: A simplification for the lab; a production system might use external sorting if intermediate data for a partition is too large for memory.
- Processing Reduce Tasks (
processReduceTask)
1func processReduceTask(task *Task, intermediateFiles map[WorkerId][]string, reducef func(string, []string) string) error {
2 Log(fmt.Sprintf("Processing reduce task with id %s for partition key %s", task.Id, task.Filename))
3
4 // Create a temporary output file in the worker's directory
5 tempReduceFile, err := os.CreateTemp(dirName, "mwt-*") // "mwt" for map worker temp (could be "rwt")
6 // ... (error handling: set task.Status = StatusError, return) ...
7 defer tempReduceFile.Close() // Ensure temp file is closed
8
9 var kva []KeyValue // To store all KeyValue pairs for this reduce partition
10
11 // Gather all intermediate data for this reduce task's partition from various map workers.
12 // `intermediateFiles` (map[WorkerId][]string) comes from the Coordinator,
13 // mapping map worker IDs to the list of intermediate files they produced for *this specific partition*.
14 for mapWorkerId, filesFromMapWorker := range intermediateFiles {
15 for _, filename := range filesFromMapWorker {
16 Log(fmt.Sprintf("Processing intermediate file %s from map worker %d", filename, mapWorkerId))
17 intermediateFile, err := os.Open(filename)
18 // ... (error handling: set task.Status = StatusError, return) ...
19
20 dec := json.NewDecoder(intermediateFile)
21 for { // Read all KeyValue pairs from this intermediate file
22 var kv KeyValue
23 if err := dec.Decode(&kv); err != nil {
24 if err != io.EOF { // Handle actual decoding errors
25 Log(fmt.Sprintf("Error decoding KV from intermediate file %s: %v", filename, err))
26 task.Status = StatusError
27 intermediateFile.Close()
28 return err
29 }
30 break // EOF reached
31 }
32 kva = append(kva, kv)
33 }
34 intermediateFile.Close()
35 }
36 }
37
38 // Sort all collected KeyValue pairs by key. This groups identical keys together.
39 // This is Step 5 of the paper: "When a reduce worker has read all intermediate data,
40 // it sorts it by the intermediate keys..."
41 // Again, this is an in-memory sort of all data for this partition.
42 sort.Sort(ByKey(kva))
43
44 // Iterate over sorted data, apply reducef for each unique key
45 i := 0
46 for i < len(kva) {
47 j := i + 1
48 // Find all values for the current key kva[i].Key
49 for j < len(kva) && kva[j].Key == kva[i].Key {
50 j++
51 }
52 values := []string{}
53 for k := i; k < j; k++ {
54 values = append(values, kva[k].Value)
55 }
56
57 output := reducef(kva[i].Key, values) // Execute user-defined reduce function
58
59 // Write output in the format "key value\n" to the temporary reduce file.
60 // This matches main/mrsequential.go and the lab's expected output format.
61 fmt.Fprintf(tempReduceFile, "%v %v\n", kva[i].Key, output)
62 i = j // Move to the next unique key
63 }
64
65 // Atomically rename the temporary output file to its final name (e.g., mr-out-0).
66 // The final output file is placed in the current directory (mr-tmp/ during tests),
67 // not the worker-specific one, as it's global output.
68 finalOutputFileName := fmt.Sprintf("mr-out-%s", task.Filename) // task.Filename is the partition key (e.g., "0", "1")
69 err = os.Rename(tempReduceFile.Name(), finalOutputFileName)
70 // ... (error handling: set task.Status = StatusError, return) ...
71
72 task.Output = []string{finalOutputFileName} // Record final output filename
73 task.Status = StatusSuccess
74 return nil
75}
- Core Logic: Gathers all intermediate
KeyValuepairs for its assigned partition (identified bytask.Filename) from the locations provided by the Coordinator (intermediateFiles). It then sorts all theseKeyValuepairs together, groups them by unique key, applies the user-definedreduceffor each key and its list of values, and writes the final output. - Data Aggregation: Reads from multiple intermediate files (potentially from different map workers) that correspond to its specific partition.
- Global Sort (for the partition): All
KeyValuepairs for the partition are sorted together in memory before reduction. This is essential for grouping values for the same key. - Final Output: Writes output to a temporary file and then atomically renames it to the final output file name (e.g., mr-out-X), which is placed in the main job directory (not the worker’s specific temp directory).
- In-Memory Sort: Similar to map tasks, all data for a reduce partition is sorted in memory.
Conclusion
Working on this MapReduce project taught me a lot about Go’s concurrency features, how to use RPC for process communication, and how the MapReduce framework organizes big data jobs. Most importantly, I learned to think about what can go wrong in distributed systems and how to handle failures gracefully. It’s been a great hands-on way to understand the real challenges behind large-scale data processing.